I have have heard plenty of people saying that desktop software is dead and that all future development will be done for the web. From my perspective, as both a buyer and seller of software, I think they are wrong. In fact, of the thousands of pounds I have spent on software in the last three years, I would guess that well over 90% of it was spent on software that runs outside the browser. The capabilities of web based applications have improved a lot in recent years, but they still have a long way to go to match a custom built native application once you move beyond CRUD applications. I don’t expect to be running Visual Studio, PhotoShop or VMWare (amongst others) inside the browser any time soon. The only way I see web apps approaching the flexibility and performance of desktop apps is for the browser to become as complicated as an OS, negating the key reason for having a browser in the first place. To me it seems more likely that desktop apps will embed a browser and use more and more web protocols, resulting in hybrid native+web apps that offer the best of both worlds.
I have have heard plenty of people saying that desktop software is dead and that all future development will be done for the web. From my perspective, as both a buyer and seller of software, I think they are wrong. In fact, of the thousands of pounds I have spent on software in the last three years, I would guess that well over 90% of it was spent on software that runs outside the browser. The capabilities of web based applications have improved a lot in recent years, but they still have a long way to go to match a custom built native application once you move beyond CRUD applications. I don’t expect to be running Visual Studio, PhotoShop or VMWare (amongst others) inside the browser any time soon. The only way I see web apps approaching the flexibility and performance of desktop apps is for the browser to become as complicated as an OS, negating the key reason for having a browser in the first place. To me it seems more likely that desktop apps will embed a browser and use more and more web protocols, resulting in hybrid native+web apps that offer the best of both worlds.
So, if Windows desktop apps aren’t going away any time soon, what language/libraries/tools should we use to develop them? It is clear that Microsoft would like us to use a .Net development environment, such as C#. But I question the wisdom of anyone selling downloadable off-the-shelf software based on .Net [1]. The penetration of .Net is less than impressive, especially for the more recent versions. From stats published by SteG on a recent BOS post (only IE users counted):
No .Net: 28.12%
>= .Net 1.0: 71.88%
>= .Net 1.1: 69.29%
>= .Net 2.0: 46.07%
>= .Net 3.0: 18.66%
>= .Net 3.5: 0.99%
Consequently deploying your app may require a framework update. The new .Net 3.5 framework comes with a 2.7 MB installer, but this is only a stub that downloads the frameworks required. The full set of frameworks weighs in at eye watering 197 MB. To find out how much the stub really downloads Giorgio installed .Net 3.5 onto a Windows 2003 VM with only .Net 1.0 & 1.1. The result: 67 MB. That is still a large download for most people, especially if your .Net 3.5 software is only a small utility. It is out of the question if you don’t have broadband. Microsoft no doubt justify this by saying that the majority of PCs will have .Net 3.5 pre-installed by the year X. Unfortunately by the year X Microsoft will probably be pushing .Net 5.5 and I dread to think how big that will be.
I have heard a lot of people touting the productivity benefits of C# and .Net, but the huge framework downloads can only be a major hurdle for customers, especially for B2C apps. You also have issues protecting your byte code from prying eyes, and you can pretty much forget cross-platform development. So I think I will stick to writing native apps in C++ for Windows for the foreseeable future.
There is no clear leader amongst the development ‘stacks’ (languages+libraries+tools) for native Win32 development at present. Those that spring to mind include:
- Delphi – Lots of devoted fans, but will CodeGear even be here tomorrow?
- VB6 – Abandoned and unloved by Microsoft.
- Java – You have to have a Java Run Time installed, and questions still remain about the native look and feel of Java GUIs.
- C++/MFC – Ugly ugly ugly. There is also the worry that it will be ‘deprecated’ by Microsoft.
- C++/Qt – My personal favourite, but expensive and C++ is hardly an easy-to-use language. The future of Qt is also less certain after the Nokia acquisition.
Plus some others I know even less about, including: RealBasic and C++/WxWidgets. They all have their down sides. It is a tough choice. Perhaps that is why some Windows developers are defecting to Mac, where there is really only one game in town (Objective-C/Cocoa).
I don’t even claim that the opinions I express here are accurate or up-to-date. How could they be? If I kept up-to-date on all the leading Win32 development stacks I wouldn’t have any time left to write software. Of the stacks listed I have only used C++/MFC and C++/Qt in anger and my MFC experience (shudder) was quite a few years ago.
Given that one person can’t realistically hope to evaluate all the alternatives in any depth, we have to rely on our particular requirements (do we need to support cross platform?), hearsay, prejudice and which language we are most familiar with to narrow it down to a realistic number to evaluate. Two perhaps. And once we have chosen a stack and become familiar with it we are going to be loathe to start anew with another stack. Certainly it would take a lot for me to move away from C++/Qt, in which I have a huge amount of time invested, to a completely new stack.
Which Windows development stack are you using? Why? Have I maligned it unfairly above?
[1] Bespoke software is a different story. If you have limited deployment of the software and can dictate the end-user environment then the big download is much less of an issue.
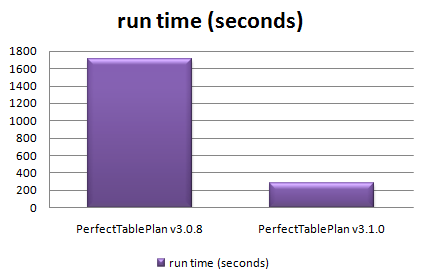
 The sink is full of washing, I am wearing odd socks and I haven’t been out of the house in days. It must be time to put out that new release. But how can I be sure my testing hasn’t missed a hideously embarrassing bug? Maybe I introduced a major bug when I made that ‘cosmetic’ change at 2am?
The sink is full of washing, I am wearing odd socks and I haven’t been out of the house in days. It must be time to put out that new release. But how can I be sure my testing hasn’t missed a hideously embarrassing bug? Maybe I introduced a major bug when I made that ‘cosmetic’ change at 2am?
 When I first released
When I first released