
This is a guest post from serial software entrepreneur Dennis Gurock.
Thinking about product positioning (and matching branding) is especially important if you build a product for a crowded market with many established competitors (and there are many reasons why this can be a good idea). We were in exactly this situation when we initially thought about building and marketing our new test management tool.
Positioning will allow you to better focus on a specific market segment to target, it makes it easier to build a clearer and stronger message to reach customers, and it helps develop the initial product vision and feature set.
What does successful positioning mean for software products? It can mean identifying a unique angle to focus on so you can stand out with your product among other products and competitors. Especially if you are entering a crowded market, this allows you to better communicate the key benefits and features you have to offer. It will help you reach the right customers and ensures that customers remember you when they look for a new product to try.
To come up with positioning for your new product, you can focus on a specific customer segment or niche that you think will be easier to market to or that you think is underserved by existing offerings. It can also help you limit the initial product scope, so you can go to market faster. Then rigorously optimizing for this initial customer segment allows you to establish a market presence and expand to other segments more easily later.
Why is positioning useful?
There are many benefits of coming up with and deciding on positioning for your new software product early on. Once you decide on the positioning, many marketing, product management and sales decisions become more straightforward.
- Clear message & benefits: it is not easy to stand out in a crowded market. Positioning allows you to come up with clear messaging so you can explain and highlight unique selling points in few words.
- Target and identify niche/marketing opportunities: it can be difficult to decide which marketing options to try, which campaigns to book and which niches to target. Focusing on a specific market segment based on the product positioning can be a great way to identify matching niches and opportunities.
- Identify customer fit during sales: one of the most important aspects of the sales process is identifying and ensuring prospects are actually a great fit for your product. It’s wasted time for both you and for your prospects to invest a lot of effort evaluating and piloting a product if they will not benefit from it. Positioning can help you quickly filter and identify which customers to focus on.
- Better focus on initial product vision: there are a lot of directions to choose when building a new product. If you don’t have a clear vision to guide you, it is easy to be distracted by different directions and work on too many things at the same time. Clear positioning makes it easy to focus product management on specific goals and use cases.
- Easier to choose features: when you start working with customers, you will (hopefully) receive a lot of feedback on features you should add. Positioning helps you decide which of these features you should actually implement. Often times the most successful products are developed by following strong opinions and saying ‘No’ to many requests.
Examples of software product positioning
Let’s look at a few examples of companies that use positioning to market and build their products. All these examples are from industries and product categories with many existing competitors and products.
- Testmo: we entered a crowded market with many established testing tools when we developed our new product. Most existing offerings either focus on manual testing, or they offer a complete ALM toolset to handle the entire development lifecycle. With Testmo we had other ideas and wanted to position it differently, focusing on unified testing. This means we combine test cases, automation and exploratory testing in a single platform. At the same time it allows us to limit the scope of the product. We won’t add our own issue tracking, or CI pipelines, or existing DevOps features. Instead of we focus on integrating with other tools customers already use.
- Another example is the documentation and wiki product GitBook. They heavily focus on software developers and position themselves as the primary tool for developers to publish user docs and to document internal knowledge. With this positioning in mind, they can focus on features that primarily make sense for developers, such as Git synchronization, Markdown support and code snippets. It also allows them to more easily market directly to software developers with a clear message.
- Then there’s the application monitoring service Checkly. There are many services and products that enable you to monitor apps and sites for downtime and notify you about issues. Checkly positions itself as a tool that enables end-to-end monitoring with flexible scripting. So it doesn’t just make simple web requests to see if a site is still live. It allows customers to write custom scripts to implement complex user flows and thereby not just check if a site is reachable, but also test the entire stack with the front-end, database, authentication and much more. This focus allows them to build more targeted features for advanced use cases and thereby provides more value to customers compared to simpler competitors.
- The popular email marketing service Campaign Monitor also started with very focused positioning. In the first few years they concentrated on providing the best possible campaign tool for web designers and design agencies. This focus allowed them to invest more in features designers needed, such as white labeling, reusable themes and live email previews. Once they established their market presence, they started to expand their customer base to capture a larger part of the overall market for newsletter tools.
These are just some examples of companies and products that have benefited from clear positioning. Of course there are also countless of examples of companies choosing not to have such clear positioning. There is nothing wrong with this and you can certainly be very successful even if you ignore these points. But more often than not positioning is a useful tool to improve focus on specific goals and customer needs, which increases your chance to build a successful software business.
Dennis Gurock is one of the founders of Testmo, a QA testing tool that unifies test case management with exploratory testing and test automation in one platform. He has been working on products that help teams improve software quality for more than 15 years.

 We tend to hear a lot about software industry success stories. But most of us mere mortals have to fail a few times before we learn enough to succeed. In this guest post William Echlin talks about the hard lessons he has learned about creating and selling software products.
We tend to hear a lot about software industry success stories. But most of us mere mortals have to fail a few times before we learn enough to succeed. In this guest post William Echlin talks about the hard lessons he has learned about creating and selling software products.






 ‘Defence in depth’ is a military strategy where the attacker is allowed to penetrate the defender’s lines, but is then gradually worn down by successive layers of defences. This strategy was famously used by the Soviet Army to halt the German blitzkrieg at the battle of
‘Defence in depth’ is a military strategy where the attacker is allowed to penetrate the defender’s lines, but is then gradually worn down by successive layers of defences. This strategy was famously used by the Soviet Army to halt the German blitzkrieg at the battle of  The sink is full of washing, I am wearing odd socks and I haven’t been out of the house in days. It must be time to put out that new release. But how can I be sure my testing hasn’t missed a hideously embarrassing bug? Maybe I introduced a major bug when I made that ‘cosmetic’ change at 2am?
The sink is full of washing, I am wearing odd socks and I haven’t been out of the house in days. It must be time to put out that new release. But how can I be sure my testing hasn’t missed a hideously embarrassing bug? Maybe I introduced a major bug when I made that ‘cosmetic’ change at 2am?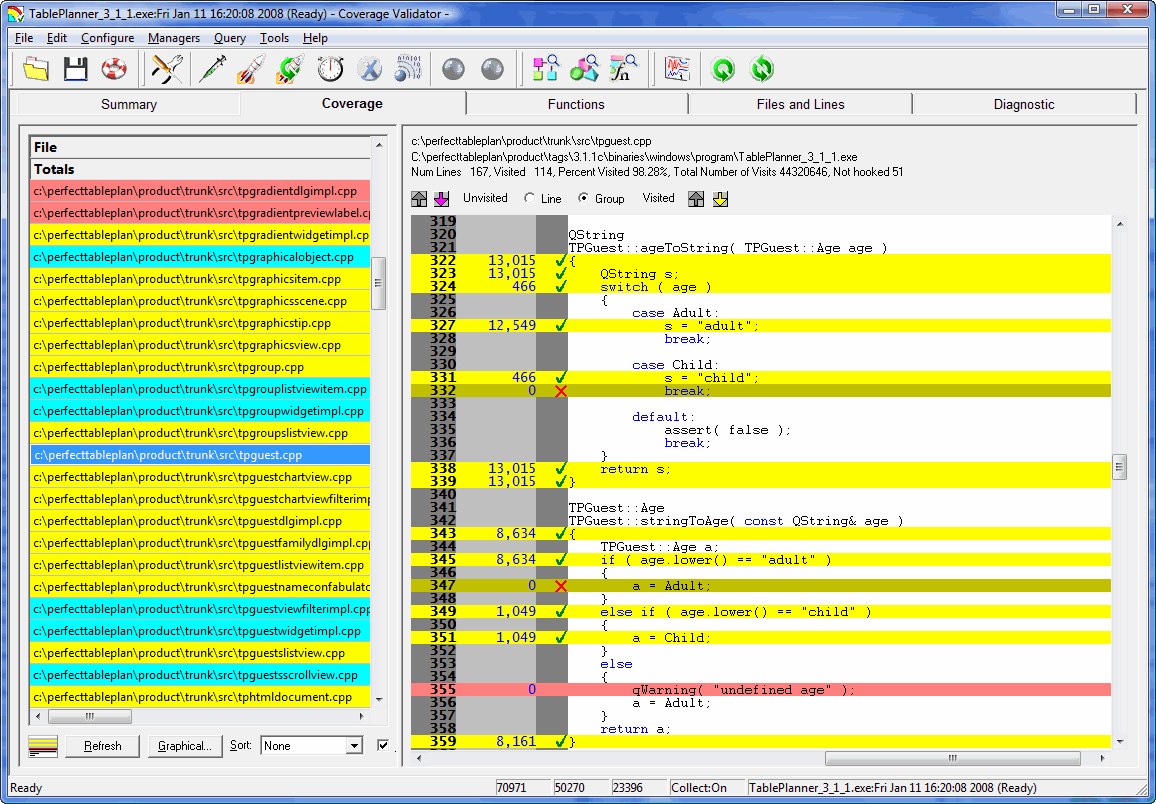

{kind=link}