There is a common pattern with paid digital advertising channels. New platforms appear with opportunities for cheap ads. Over time, more and more advertisers start to use the platform. Supply and demand drives up the price per click. The platform owners also do everything they can to nudge click prices ever higher. Consequently ad prices rise until companies selling inexpensive products (like mine) can’t afford to bid high enough to get any clicks. But usually a new platform comes along and the dance starts again.
I’ve seen this play out over the 20 odd years that I have been using Google Adwords. In the early days I could get a decent number of clicks at an affordable price. But the price has risen now to the point where I get very few clicks for any price I am prepared to pay. I need a new advertising channel. I tried advertising on Reddit, but that was a resounding failure. I wondered if it might be worth advertising in the new hotness, ChatGPT. So I did some investigating. Here is what I have found out so far, from reading their documentation and other sources.
ChatGPT advertising is structured in a similar way to Google Adwords, with campaigns, ads, auction bids and conversion tracking. But, instead of matching keywords in search terms, you describe contexts in which your ads should appear. This should be less hassle than defining hundreds of search keywords. But it is hard to know how well targetted the ads will be or how well they will convert into sales. Some experimentation is required to answer that.
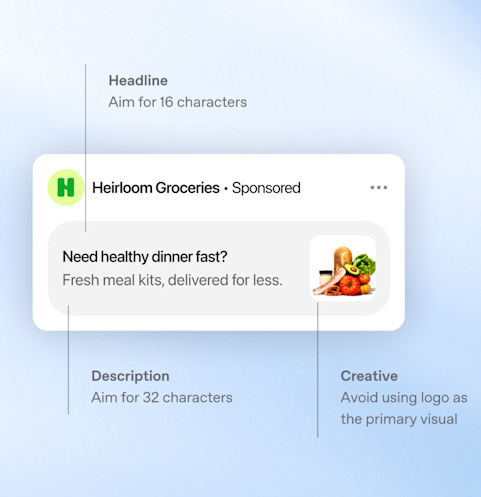
The ad format is fairly simple: name, headline, short description and small a image.
You can currently only advertise to customers on free plans based in USA, Canada, Australia and New Zealand.
In their own documentation, ChatGPT says: “Advertisers can set custom max bids for their CPC campaigns. We recommend a starting max bid of $3-5 USD per click.”. Yikes. I know they have massive costs to subsidize, but there is no way I can make a profit at $3 per click for my $99 data wrangling software Easy Data Transform. Given a typical 1% conversion rate I would be paying $300 per sale. However, bid recommendations are always very self serving, and can be taken with a large pinch of salt. It is likely that you can get clicks much cheaper. Especially given that there are currently relatively few advertisers compared to the number of users.
So far, so good.
The fly in the ointment is the minimum spend. $50k (down from $250k!). Ah. Maybe not. That minimum commitment may come down over time. But, by the time it is low enough for me to experiment, the bids will almost certainly be too expensive for it to be profitable to someone selling $99 software licenses. The search for affordable advertising channels continues.
** Update 29-May-2026 **
There are reports that the $50k minimum spend has now been dropped. However advertising is only open to US advertisers. More details.
Please consider re adding the option to convert from one time zone to another as was available in [Easy Data Transform] version 1.x. See the attached screen dump.
Easy Data Transform has never had a time zone conversion feature, so that is a bit strange. Although . But the screenshot really set off alarms bells as, despite saying “Easy Data Transform v1.11.2” in the title bar, that is not our software!
I thought that someone was trying to pass of their product as ours and did a search. But I couldn’t find any reference to another piece of software called “Easy Data Transform”. I emailed the customer to ask where they had got the software from. The reply came back:
The screenshot was from a ChatGPT output – maybe hallucinating.
Wow. Not only had ChatGPT hallucinated the feature, but also a fever dream screenshot of the user interface, with the non-existent feature. It looks like a real screenshot at first glance, but the icons are a giveaway if you look closer.
For reference, this is what the actual user interface looks like:
ChatGPT has got some of the input types, transforms and menus correct. But otherwise it looks quite different.
I had another brush with AI hallucinations when I asked MS Copilot how to perform ‘one hot encoding’ in Easy Data Transform. It came back with a very plausible and confident sounding answer, including this summary of the transforms required:
Just one problem – only 1 of these 4 transforms actually exists (Split Col). It hallucinated the other 3!
Customers are increasingly typing questions into AIs, rather than reading documentation or asking on a forum. That is good news if it means that the customer gets a quick and accurate answer without troubling busy developers. But it is very bad news if they are getting incorrect answers, especially when these answers look plausible and are confidently presented. It is galling enough that AIs are stealing all our web traffic, without them giving our customers bad support advice as well! Wild times are ahead.
Ps/ Time zone conversion and one hot encoding are now available in the latest version of Easy Data Transform.
Twice this week, I have come across embarrassingly bad data.
The first instance is the UK government’s fuel finder data. This is a downloadable CSV file of fuel station locations and prices from around the UK. A potentially very useful database, especially during the current conflict in the Middle East. A customer suggested it as a possible practice dataset for my data wrangling and visualization software, Easy Data Transform . So I had a quick look and spotted some glaring errors within a few minutes.
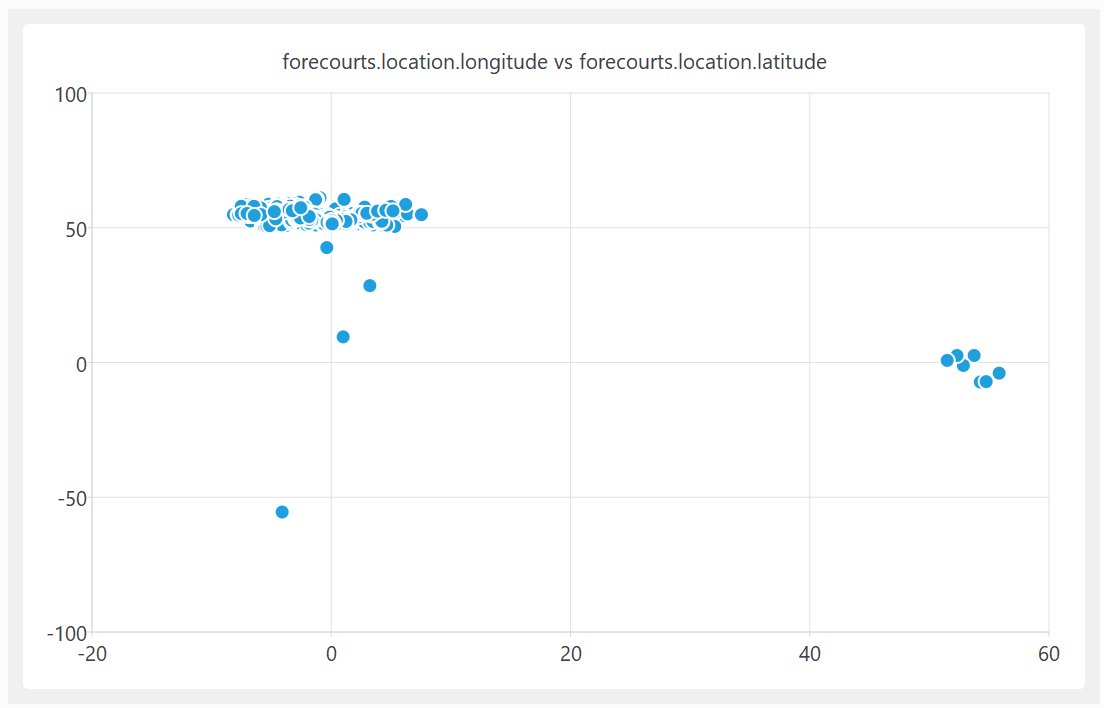
A quick plot of the latitude and longitude shows some clear outliers:
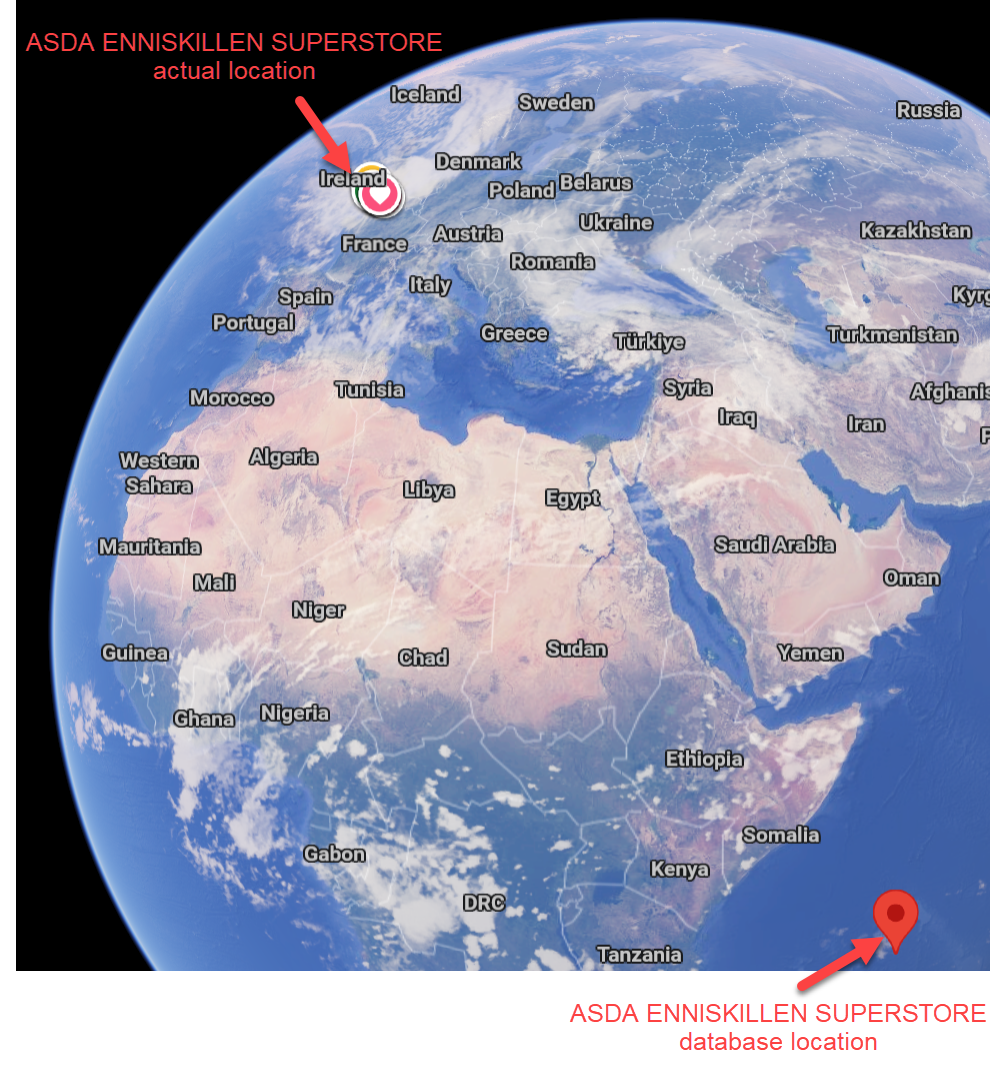
On further investigation, some of these UK fuel stations are apparently located in the Indian and South Atlantic oceans. In at least one case, it looks like they got the latitude and longitude the wrong way around.
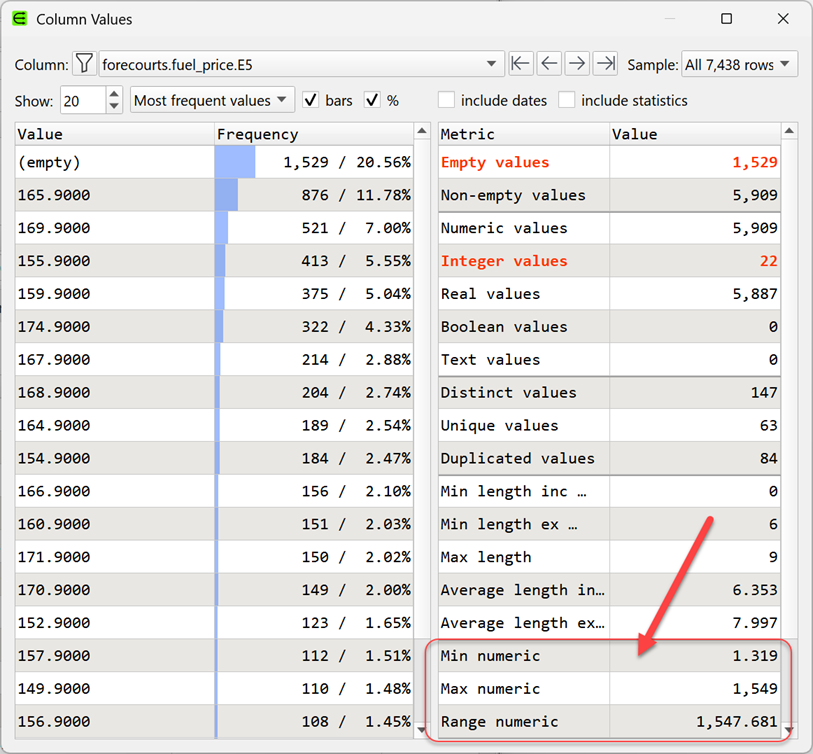
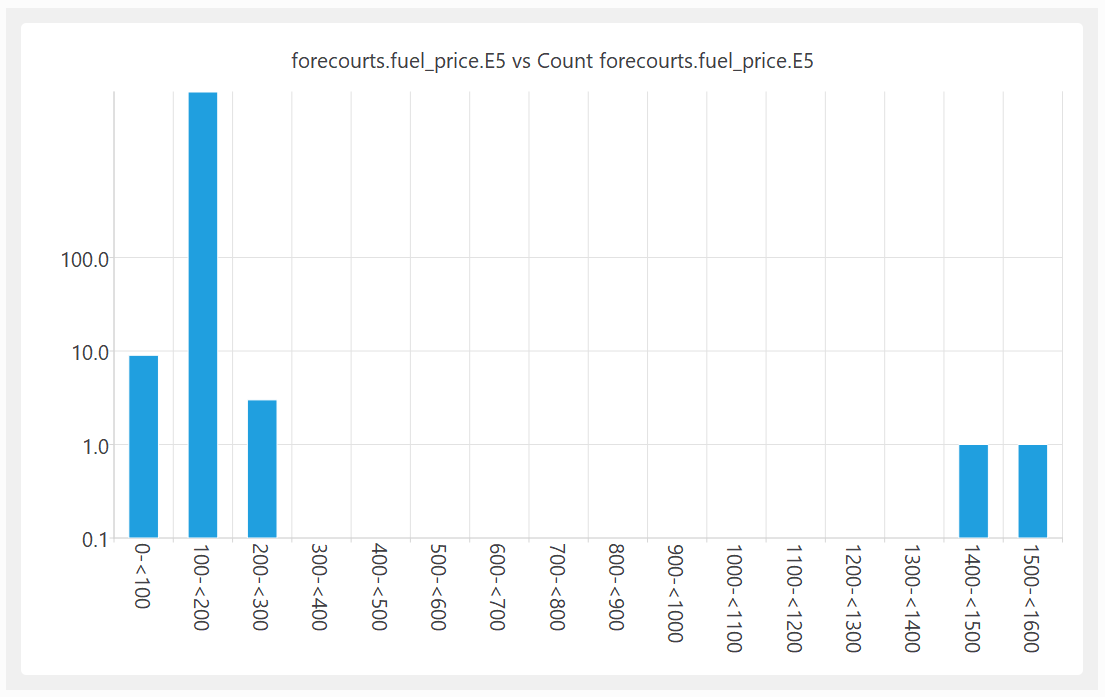
A quick look at the fuel price columns also shows some major issues:
The ratio between the most expensive and cheapest fuel (per litre) is 1538:1. Clearly wrong.
Shown as a histogram with a logarithmic Y axis:
I am guessing that the reason for this bad data is that the fuel stations are submitting their own data and, humans being humans, they make mistakes. But then the government is publishing the data without even the most basic checks. That just isn’t good enough.
I reported the problem on 22-Mar-2026. They acknowledge my email on 24-Mar-2026 (“Thank you for sharing this, we have passed this on to the technical team to have a look at.”). The CSV file published on 29-Mar-2026 still has the garbage data.
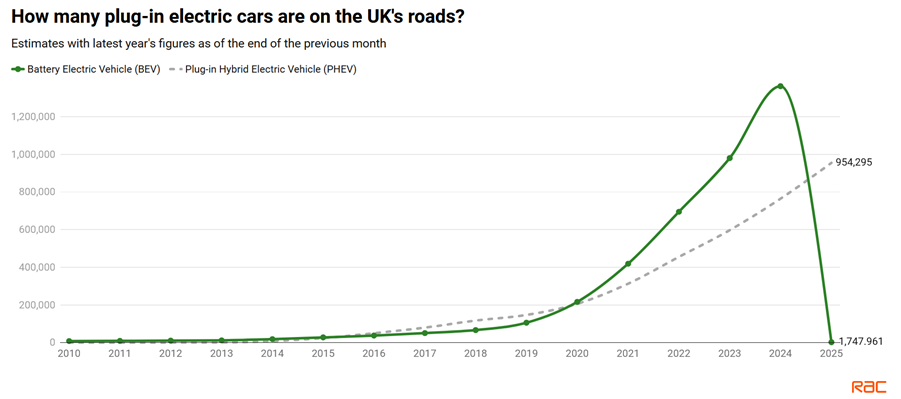
The second instance is a report on electric cars from UK motoring organization, the RAC. The first graph in the article is this:
Did the number of Battery Electric Vehicles on the UK’s roads suddeny drop from ~1.4 million in 2024 to ~0.0017 million in 2025? What happened to those ~1.4 million vehicles? I’m guessing that someone got their thousands and millions mixed up. But then they published the report with this glaring error. Did anyone mathematically literate even check this graph?
Lousy data undermines trust in institutions and can lead to bad decisions. I fear we are heading for a future where LLMs generate data, which people don’t bother to properly check. This data is then used train LLMs. The error is then much harder to spot once it is served back without the original source by LLMs. A slop-apocalypse.
Authors should have their work proof read, programmers should test their code and data people should do basic data validation. Let’s take some pride in our work.
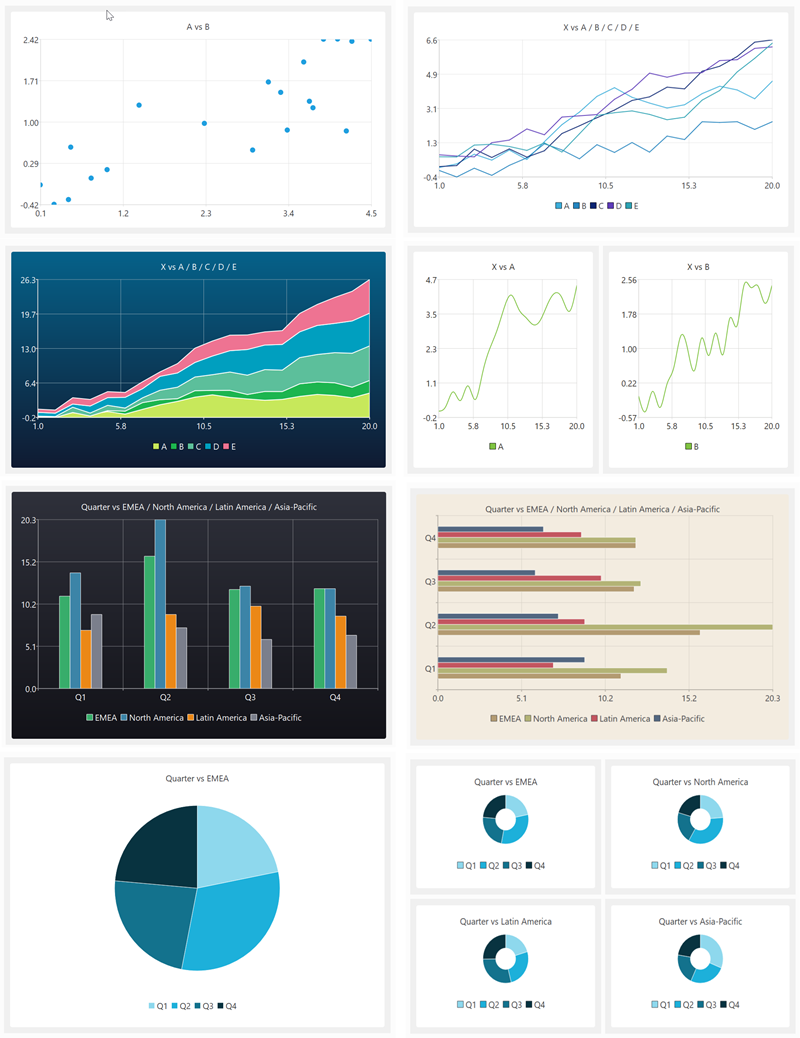
My data wrangling product, Easy Data Transform, got a major upgrade yesterday, with the addition of data visualization capabilities. Here are some examples of what it can produce in a few clicks:
You can see this new visualization feature in action in the video below:
(Likes and subscribes help me with the YouTube algorithm and are much appreciated)
Human brains are highly developed for visual processing. But data is often messy and in the wrong form for visualization. So data wrangling and visualization, tightly integrated together, is a powerful combination. It was a lot of work, but it makes Easy Data Transform a much more complete, end-to-end, solution. No more pasting data into Excel to get a chart!
At the same time, I have segmented Easy Data Transform into 2 products: Easy Data Transform Core Edition (data wrangling, one-time fee $99) and Easy Data Transform Advanced Edition (data wrangling+visualization, one-time fee $198). The Advanced Edition is a paid upgrade from the original product. Optional, of course. I sweetened the deal with a time-limited discount for existing customers who want to upgrade to Advanced Edition. The response from Easy Data Transform customers has been very positive.
Have you got some messy data, you want to turn into insights? Why not give Easy Data Transform Advanced Edition a try? It:
Runs natively on Windows and Mac.
Is drag and drop (no syntax to remember).
Does not store your precious data on someone else’s server.
Is deterministic and will not hallucinate!
Can process millions of rows in seconds.
Can create re-usable templates for repeatable processes.
You can download a free trial here. And you can get 15% off Easy Data Transform Advanced Edition until 17-Jul-2026 using this discount link.
The concept of shareware appeared in the 1980s. Developers would use relatively primitive tools to create their software, then promote it via fanzines, user groups and bulletin boards to a niche audience of shareware fans. If you wanted to try the software, you would have to get hold of a floppy disk with it on. And, if you wanted to buy a licence, you would generally have to post a physical cheque to the developer. This was being an Indie developer in hard mode. A few people made a lot of money, but most vendors made modest returns on their efforts.
I started selling my first software product in 2005. This was a good time to start up as an independent software vendor. High quality compilers, IDEs, debuggers, version control systems and web servers were widely available and mostly free. The market for software was growing, as more and more people purchased PCs and Macs. Payment processors were starting to streamline online payments. But the real revolution was being able to distribute your software worldwide via an increasingly ubiquitous Internet. And getting noticed by potential customers, while never easy, was generally achievable through writing content for search engines to find, paid online ads (such as Google Adwords pay per click), download sites or even ads in physical magazines. With a lot of hard work and a bit of luck, it was quite possible to make a decent living.
Things have continued evolving at a rapid pace over the 20 years I have been selling software. Development tools have continued to improve. Mobile and web-based software has become mainstream. App stores have appeared. Outsourcing became a thing. Subscription payment models are increasingly common. Mostly these changes haven’t affected my business too much. But recently things have begun to feel noticeably harder.
LLMs have made a major impact. While I don’t worry that LLMs will do a better job than my seating planner software, data wrangling software or visual planning software any time soon (my main competitor remains Excel), everyone is noticing that their web traffic is falling. People increasingly read LLM summaries rather than clicking on search engine links or the accompanying ads. Maybe the LLM will include a link to the website that they ripped off the content from, but probably they won’t. So writing content in the hope of traffic from search engines is becoming less and less of a viable strategy to get noticed.
Other promotional channels are getting squeezed as well. Online ads are increasingly expensive and rife with click fraud. This makes it hard to get any chance of a return, unless lifetime customer value is hundreds of dollars. Google Adwords is a case in point. In the early days, I could get lots of targeted clicks at an affordable price. But Google have done everything they can to raise bid prices and generally enshittify Adwords, so they can grab more and more of the value in every transaction. I now get barely any clicks at bid prices I am prepared to pay.
One of the few useful promotional channels left is YouTube. But it is very time-consuming to produce videos and the amount of competition is huge. I fully expect generative AI to erode its value over time, as AI slop floods the channel.
Typically promotional channels start off great for vendors and become less great over time (the law of shitty clickthrus). But then new promotional channels appear and the dance starts again. But there just doesn’t seem to be much in the way of viable new channels appearing for Indie vendors like myself. My experiment with advertising on Reddit did not go well.
LLMs potentially also make software easier to write, which is a double-edged sword. It might help you code features faster, but it also lowers the barrier, so that more people can compete. Even if your new competition is bug riddled garbage, ‘vibe coded’ by someone who doesn’t know what they are doing, it still makes it harder for your product to get noticed.
The general cost of living crisis hasn’t helped either. The super-rich are making out like bandits, but everyone else has less disposable income. And that is only going to get worse when the current AI funding circle-jerk implodes.
Each of the different software platforms also have their own issues.
Downloadable software has fallen out of fashion and the market is shrinking as increasingly people expect software to be web-based. People are also wary about downloading software onto their computers, in case it contains malware.
Web-based software is more of a service than a product and is expected to be available 24×7. Expect to get lots of very unhappy emails if your server falls over. And woe betide you if your customer data is hacked. Disappearing off somewhere for a few days without an Internet connection is not really viable, unless you have employees.
Mobile-based software is expected to be free or, at best, very cheap. So requires huge scale to make any decent return. And that is tough when there are some 2 million apps in the iPhone app store. You are also at the mercy of app store owners, who really don’t have your best interest at heart.
The new wave of AI tools must be creating new opportunities, but it seems these opportunities are mostly there for big companies, not for Indie developers. And it is very risky to build your product as a thin layer on top of someone else’s platform. Ask people who built tools and services on top of Twitter.
It feels that it is getting harder for small software vendors, like myself, to make a living. Of course, this could be just the ramblings of a 50-something-year-old, looking back through his rose-tinted varifocals. What do you think? Has it got harder?
If you want to show indie software vendors some love, check out all the great indie software for Mac and Windows (including my own Easy Data Transform and Hyper Plan) on sale at Winterfest.
The application icon for my data wrangling software looks like this on a Mac up to macOS 15.x:
However, Apple has once again nuked everything from orbit. Now it looks like this in macOS 26 Tahoe when the application is inactive or if you choose any Icon & widget style apart from Default:
Thanks Apple. It is such a joy to develop for Mac.
With some help from a designer and hours of going around in circles, I have finally managed to fix things to support the new ‘liquid glass’ look. This is how it should look in the next release, depending on the setting in Appearance>Icon & widget style:
Default
Dark
Clear/Light
Clear/Dark
Tinted
I’m not convinced it is an improvement in terms of usability. But, at least my app icon doesn’t look like shit.
What you need to know
The new macOS 26 icon format is .icon. It is a folder full of various resources and is totally different to the old .icns format.
The .icon file can be created by Apple Icon Composer. I used a freelancer on Fiverr who did a good job of converting my existing vector artwork and was very cheap. The .icon file should contain a maximum of 4 groups (which seem to be like layers) other it won’t compile to a resource properly.
Note that macOS hide the extension of .icon folders by default, which was a source of some confusion.
The .icon file then has to be processed into an Assets.car file using actool. For example:
xcrun actool application.icon --compile ./icons/macosx --output-format human-readable-text --notices --warnings --errors --output-partial-info-plist temp.plist --app-icon Icon --include-all-app-icons --enable-on-demand-resources NO --development-region en --target-device mac --minimum-deployment-target 26.0 --platform macosx
You will need to change the bold parts above, as appropriate.
I had to update my Mac laptop to macOS 26, Xcode 26 and the macOS 26 SDK for the above to work.
You can check the Assets.car file using assetutil to create a .json file listing the contents:
You will need to change the bold part above, as appropriate. I believe the string value if based on the file stem of the original .icon file. But I’m not 100% sure about that. Look at the .json file produced by assetutil for clues. Mine contained this:
The temp.plist file generated by actool is apparently supposed to give you a .plist file that refers to the icon resource. It didn’t and was completely useless.
Then place both Assets.car and your old .icns file in the Resource folder of your application (before you sign it). That way it should look ok on both macOS 26 and earlier OSes.
If you develop using XCode, it will probably do some of the above for you. I develop in C++/Qt using Qt Creator, so I had to do it all manually.
I was able to generate the Assets.car on macOS 26 and then incorporate it into the build on my macOS 12 development machine.
I hope the above saves someone a few hours. Now I need to repeat the process for PerfectTablePlan.
You might also find this post useful (where I got some of the information):
When people are trying to convey a quantity, they will generally try to compare it to something that they think people already have a feel for. For example, ‘weighing as much as 10 elephants’ or ‘twice the area of a tennis court’. But people often come up with terrible comparisons, and this grates on my nerves. So I have done a little side project to generate comparisons for you. I named it ‘How many elephants’ as elephants (and Jumbo jets) seem to figure a lot in these comparisons.
It allows you to create comparisons for:
Length/Height
Area
Volume
Mass/Weight
Time
Velocity/Speed
Energy
I might add more dimensions, such as force, acceleration and pressure, later on.
It is just a single page of HTML + CSS + JQuery. I used Microsoft Copilot to generate the image and, as a sort of turbocharged Stackoverflow, to help me with the coding.
Did I miss a good comparison or make a mistake? Feel free to give some feedback in the comments.
My seating planner software, PerfectTablePlan, is now at v7. Major upgrades are paid (discounted 60% compared to new licences), which means I have done 6 cycles of paid upgrades. I was curious about how long it took people to upgrade, and what percentage of sales are upgrades. So I took a few minutes to crunch the numbers direct from my licence key database, using my data wrangling software, Easy Data Transform.
Here are the number of upgrade licences I sold for each week after the major upgrade. Each release is in a different colour. The values are normalised so that the peak is the same height for each release:
Upgrade licences sold per week after a major upgrade, across 6 upgrades
That looks rather messy. So here it is with the values for the 6 upgrades summed:
Upgrade licences sold per week after a major upgrade, summed across 6 upgrades.
There is a long tail of upgrades. Even when the gap between releases was 6 years, I was still getting regular upgrade purchases.
With the v5 to v6 upgrade it took:
23 weeks before 50% of the upgrades were sold.
74 weeks before 75% of the upgrades were sold.
So it isn’t a neat exponential decay.
This table shows how many users actually upgraded from v5 to v6:
Edition
Upgraded
Home edition
12%
Advanced edition
31%
Professional edition
45%
Most of the Home edition purchasers are buying a licence for a one-off event, such as a wedding. So it is not surprising that they are much less likely to upgrade. But I think it also shows that less price-sensitive customers are significantly more likely to upgrade, even when the upgrade is more expensive.
This graph show the percentage of PerfectTablePlan licences sold each month that were upgrades, over the 20 year life of the product:
Percentage of sales that are upgrades per month.
You can see that upgrades are still increasingly important over time. Upgrades are worth less than new sales, so selling 80% upgrade licences in a month doesn’t mean 80% of revenue is from upgrades. However, upgrades are still an increasingly significant source of revenue for us. I’m glad I never agree to free upgrades for life.
Could I have made more sales with more frequent major upgrades? Definitely. But I was also working on other projects. And I am not out to squeeze every last penny out of my loyal customers.
Could I have made more sales with a subscription model? Possibly. But subscriptions weren’t really a thing for desktop software, when I started 20 years ago. And I never felt like making a major change to a licensing model that had worked well for me, so far.
I am always on the lookout for cost and time effective ways that I can market my software products. Previously, I have had quite a lot of success with Google Adwords Pay Per Click ads. However, the law of shitty clickthroughs means that advertising platforms generally get less and less profitable (for the advertisers) over time. And Google Adwords is a case study of that law in action. As Reddit is a less mature advertising platform, I thought it might still offer opportunities for a decent return. So I decided to experiment with advertising my data munging software, Easy Data Transform, on Reddit.
[By the way, I understand that nobody goes to Reddit because they want to see ads. But commercial products need to market themselves to survive, and Reddit probably wouldn’t exist without ads. Yay capitalism.]
Setup
The basic process to get started with Reddit Ads is:
Sign up for a Reddit Ads account.
Enter your details and credit card number.
Create a campaign.
Create one or more ad groups for your campaign. Choose a bid for each ad group, which countries you want it shown in and who you want it shown to.
Create one or more ads for each group.
Add the Reddit tracking pixel to every page of your website.
Set up conversion goals.
All pretty standard stuff for anyone who has used Google Adwords. The twist with Reddit is that you can advertise to communities (sub-Reddits), rather than based on search keywords. For example, Easy Data Transform is a much better tool for most data wrangling tasks than Excel, so I can bid to show ads targeted at Excel users in communities such as: reddit.com/r/excel/ and reddit.com/r/ExcelTips/.
Like Adwords, there are various ways to bid. I don’t want the advertising platform to set the bid prices for me (because I’m not insane), so I opted for fixed price bids of between $0.20 and $0.40 per click. Some of the ad groups suggested much higher bids than that. For example, the suggested bid for my Excel ad group is $0.79 to $4.79 per click!
However, Easy Data Transform is only a one time payment of $99. Paying more than $0.40 per click is unlikely to be profitable for me, especially when you factor in support costs. So that is the maximum I was prepared to bid. Also, the suggested bids are just the ad platform trying to push up the bid price. Something that anyone who has used Google Adwords will be all too familiar with. I was still able to get clicks, bidding significantly less than the recommended minimum.
I also set a daily maximum for each ad group, just in case I had messed up and added a zero in a bid somewhere.
I created multiple ads for each ad group, with a range of different text and images specific to the communities targeted. Here are some of the ones I ran in the Excel ad group:
I didn’t try to use edgy images or memes, because that isn’t really my style. There is an option to turn comments on below ads. As Reddit users are generally not well-disposed to ads, I didn’t try turning this on.
Based on hard-won experience with Google Adwords, I only set my ads to run in wealthy countries. I also restricted my ads to people on desktop devices as Easy Data Transform only runs on the desktop.
When Easy Data Transform is installed, it opens a page on my website with some instructions. So I used this to set up the Reddit conversion tracking to count the number of times a click ended up with a successful install of either the Windows or Mac version of Easy Data Transform.
I monitored the performance of the ads and disabled those that has poor click through or conversion rates and made variants of the more successful ones. Darwinian evolution for ads. I ended up creating 70 ads across 15 ad groups, targeting 50 communities.
I wasted an hour trying to get Reddit to recognize that I had installed their tracking pixel. But, overall, I found the Reddit Ads relatively simple to setup and monitor. Especially compared to the byzantine monstrosity that Google Adwords has become.
Reddit advertises a deal where you can get $500 of free ads.
But the link was broken when I clicked on it. Someone else I spoke to said they had tried to find out more, but gave up when they found out you had to have a phone call with a sales person at Reddit.
Results
I ran my experiment from 08-Jul-2025 to 31-Jul-2025. These are the stats, according to reddit.
Spend
$851.04
Impressions
490,478
Clicks
3,585
Windows installs
177
Mac installs
63
Total installs
240
Click Through Rate
0.73%
Cost Per Click
$0.24
Click to install conversion rate
6.59%
Cost Per Install
$3.55
I generally reckon that somewhere around 10% of people who install are going on to buy. So $3.55 per install would mean around $35.50 cost per sale, which is reasonable for a $99 sale. So that all looks quite encouraging.
But, comparing the Reddit number to the numbers I get from Google Analytics and my web logs, I think the Reddit numbers are dubious. At best. In a week when Reddit says it sent me 1174 clicks, Google Analytics says I received 590 referrals from Reddit and my web log says I received 639 referrals from Reddit. Some of the difference may be due to comparing sessions with clicks, time zones etc. But it looks fishy.
The discrepancy is even greater if you look at conversions. The total installs per week reported by Google Analytics and my web logs didn’t go up anything like you would expect from looking at the Reddit conversion numbers. If you dig a bit further, you find that Reddit uses ‘modeled conversions‘ to:
“Gain a more complete view of your ads performance with modeled conversions, which leverages machine learning to bridge attribution gaps caused by signal loss.”
Uh huh. Sounds suspiciously like ‘making shit up’.
And then there are the sales. Or lack of. I don’t have detailed tracking of exactly where every sale comes from. But I estimate that my $851 outlay on ads resulted in between $0 and $400 in additional sales. Which is not good, given that I don’t have VC money to burn. Especially when you factor in the time taken to run this experiment.
The top 5 countries for spend were:
Italy
Spain
France
Germany
Singapore
The US only accounted for 0.28% of impressions, 13 clicks and $3.81 in spend. Presumably because the US market is more competitive, and I wasn’t bidding enough to get my ads shown.
You can look at various breakdowns by country, community, device etc. This is helpful. But some of the breakdowns make no sense. For example, it says that 41% of the click throughs from people reading Mac-related communities were from Windows PCs. That sounds very unlikely!
But the worst is still to come. Feast your eyes on this Google Analytics data from my website:
Average engaged time per active user (seconds)
Engaged sessions per active user
Google / organic
33
0.75
Successfulsoftware.net / referral
31
0.74
Youtube.com / referral
27
0.86
Chatgpt.com / referral
24
0.69
Google / CPC
16
0.65
Reddit / referral
8
0.25
8 seconds! That is the mean, not the median. Yikes. And 75% of the sessions didn’t result in any meaningful engagement. This makes me wonder if the majority of the Reddit clicks are accidental.
I had intended to spend $1000 on this experiment, but the results were sufficiently horrible that I stopped before then.
If I had spent a lot of time tweaking the ad images and text, landing pages, communities and countries, then I could probably have improved things a bit. But I doubt I could ever get a worthwhile return on my time and money.
If the lifetime value of a sale is a lot more than $99 for you, or your product is a good fit for Reddit, then Reddit Ads might be worth trying. But be sure not to take any Reddit numbers at face value.
Bearing in mind that I am a developer and NOT A LAWYER, it is my understanding that if:
You host a discussion forum.
and
You, or any of your users, are based in the UK.
Then the UK government considers you subject to the UK Online Safety Act. Even if your forum is about hamsters. Failing to comply could get you a fine of up to £18 million or 10% of the company’s global revenue, whichever is greater.
That got your attention, didn’t it?
How can you be subject to UK law if you don’t have a presence in the UK? Good question. Are they going to extradite you or grab you if you come to the UK on holiday? I have no idea. Isn’t it all a bit over the top for a small customer forum? I think so. What if every country starts trying to apply their laws to citizens in other countries? Bigger yachts for the partners in law companies, I guess.
If you are outside the UK, you will have to make your own decision about whether to care about this law. But I am based in the UK. So I definitely need to care about it – even though my Discourse forum is a highly moderated, technical forum about data cleaning, transformation and analysis, with no porn, violence or gambling content.
There are hundreds of pages of guidance about this new law, which covers massive companies, such as Google and PornHub, as well as my little company. But my understanding is that the minimum a forum owner needs to do is:
Have an online safety policy
Assess the likelihood of children accessing your site
Assess the risk of harmful content
Take appropriate measure based on the above
Regularly update your assessments
Depending on your assessment and the type of content, you may need age verification checks or other measures. I assess that my data wrangling forum is not attractive to children and very unlikely to have harmful content, so I have not gone through the massive ball-ache of adding age verification.
For good measure, I have also disabled the ability of customers to direct message each other. As that is something I can’t moderate and don’t want to be responsible for.
This is 2025, so I generated my online safety policy and assessments with some help from Microsoft CoPilot. Feel free to use them for some inspiration if you need to generate your own policy. But please don’t copy them word-for-word.
Incidentally, generating documents that none of my customers will ever read seems the perfect use case for LLMs.
I really hope I don’t get forced to add age verification. I would rather shut down the forum.