In theory an Internet based software business isn’t tied to any particular geographical location and can be run from a laptop anywhere there is an Internet connection. So why not travel the world, financed by your business? Trygve & Karen Inda are doing just that. They kindly agreed to write this guest post discussing the practicalities of running a nomadic software company.
In theory an Internet based software business isn’t tied to any particular geographical location and can be run from a laptop anywhere there is an Internet connection. So why not travel the world, financed by your business? Trygve & Karen Inda are doing just that. They kindly agreed to write this guest post discussing the practicalities of running a nomadic software company.
The freedom to wander aimlessly around the planet, visiting whichever countries you want, is something many people dream about. We have actually achieved it through our microISV. For the past six years, we have been living and working in numerous countries, with nothing more than our Mac laptops, backpacks, assorted cables and adaptors and an insatiable thirst for adventure.
We were thirty years old, with no kids and no debt, working steady jobs in Reno, Nevada, and had a small microISV on the side. It was a “nights and weekends” business that earned us dining out money, or even covered the rent in a good month. After September 11th, my husband Trygve’s day-job slowly went away, giving him more time to devote to our microISV. By March 2002, when we first released EarthDesk, the microISV had become his full-time job.
The response to EarthDesk was phenomenal and we soon realized that we could move overseas, bringing our microISV with us. Within several months, we had sold the bulk of our possessions, moved out of our apartment in Reno and purchased one-way tickets to Tbilisi, Republic of Georgia.
The experiment begins
For six months, we tried to manage our software business while teaching English and doing odd jobs for NGOs, newspapers and radio stations. We had brought with us two Mac laptops (a PowerBook G4 and an iBook G3), which were both maxed out as far as hard drive and memory were concerned, an extra battery for the G4, an external keyboard, a digital camera, and various cables and worldwide plug adaptors. We had also brought a CD case full of original software discs.

Tbilisi home office
In the end, the multiple infrastructure problems that plague the Republic of Georgia (mostly a serious lack of electricity) proved too much for us to bear. We escaped to Germany, carrying 170 pounds of stuff, including our two laptops, a UPS we had purchased in Tbilisi and a Persian carpet we had bargained for while on Christmas holiday in Dubai.
After a few weeks recovering in Germany, we spent a few months in Prague, Czech Republic. When the cold weather arrived, we flew south and spent eight months travelling around the Indian Ocean, South East Asia and Oceania. Shortly thereafter, we landed a software development contract in Dubai and relocated there, but regularly escape to Prague during the blistering summer months. We currently own a flat in central Prague and have considered buying a flat in Dubai.

Kampala, Uganda
By keeping a small base in one or two countries, we can have a “home”, a decent place to work and a life, while still taking long trips with the backpacks. Running the business from an apartment in the developed world is fairly straightforward. What’s challenging is running the business from a backpack while spending several months on the road.
The essentials
Everyone wants to sit on a beach and work only four hours a day, but the reality is a little different. If you are actually running your business, you’ll spend as much time working on the beach as you would in a cubicle. It’s certainly possible to work only an hour a day for a few weeks, but to develop and grow your business, you will need to spend time actually working, rather than sightseeing. It’s not a permanent holiday, but rather an opportunity for frequent changes of scenery.
As a practical matter, you can only travel with what you can carry and a good backpack with detachable day-pack is the only serious option. Since you are carrying a few thousand dollars worth of equipment, security becomes an issue, especially in poorly developed parts of the world. We generally stay in the least expensive hotels we can find that have adequate security and cleanliness, while occasionally splurging on something nicer to maintain our sanity. It is very important to budget properly for long trips. For some people this may be as much as $200/day, and for others it may be only $50/day, but managing expenditures is even more important when on the road. Of course you’ll soon realize that for the same money spent during 4 days in London, you could spend weeks in South East Asia or poorer parts of the Middle East.
On journeys of a month or more, we generally bring two up-to-date Mac laptops (currently 15″ and 17″ MacBook Pros), worldwide plug adaptors, software CDs, two iPods (one for backing up data), a digital camera and two unlocked 4-band GSM mobile phones. For longer-term backup we burn a data DVD about once per month and post it home.
Essential software includes Excel, Entourage, Filemaker Pro, Skype, iChat and, of course, the Apple Xcode Developer Tools. Speed Download saved us in Tbilisi because of its ability to resume downloads after our dial-up internet connection dropped the line, which it did every four minutes!
Surprisingly, the best Internet we have found in the developing world was in Phnom Penh. WiFi can often be found at big hotels, but it is more common to connect via Ethernet in a cafe, where a basic knowledge of Windows networking will allow you to configure your laptop to match the existing settings of the cafe’s PC. In the least developed countries, modems are still the norm.

Kigali, Rwanda
One important consideration, especially in countries where censorship is common, is that many places require you to use their SMTP server for outgoing mail. This may not work with your domain as a return address. To get around this, it’s useful to have a VPN, such as witopia.net, and an SMTP server at your domain.
Visas, taxes and other nasty stuff
If you have a western passport, visas usually only become an issue when you want to stay somewhere more than three months. Often, it is possible to do a “visa run,” in which you briefly leave the country and immediately return for another three months. Many countries make it easy to set up a local company, which can allow you to obtain longer-term residency visas, but there is a lot of paperwork involved with this. Staying more than six months as a “tourist” anywhere can be a problem as you’ll almost certainly have to deal with immigration issues.

Hong Kong
Although Dubai has straightforward immigration procedures and is a fabulous place to spend winters, the UAE Government blocks more websites than just about any other country on Earth. Even Skype is blocked because the local telecommunications company doesn’t want any competition. Unless you are able to find a way around the blocks (wink, wink), running any kind of internet business from Dubai will be fraught with difficulty.
Even if you are living in a tax haven, if you are a US Citizen, you can never fully avoid US taxes, although you can take advantage of the Foreign Exclusion. Local taxes aren’t really an issue if you’re just a “tourist” spending a few weeks in a country, but they can become an issue for long-term stays. If you are planning to stay somewhere for more than a couple months, and “settle”, you’ll need to research tax ramifications.

Sana, Yemen
Since we left the US, our taxes have become much more complicated. Fortunately, we found an American tax attorney to handle our annual filings. He lives abroad and therefore understands the Foreign Exclusion and other tax laws regarding expats. For our microISV, payment is handled online by two providers (always have a backup!), and ends up in a company account in America. We use a payroll service to pay our salaries into personal accounts, which we can access by ATM. We also have established a managed office in Nevada to act as our company headquarters and handle mail, voicemail and legal services.
We have no regrets about having left the US for our big adventure. We have truly lived our dream of being able to travel indefinitely, but sometimes it is wearying not knowing which country we will be living in just a few months into the future. Our ultimate goal is to own two properties on two continents so that we can travel between them with just a laptop.
by Karen Inda
photographs by Trygve and Karen Inda
Trygve & Karen Inda are the owners of Xeric Design. Their products include EarthDesk, a screensaver with a difference for Windows and Mac. They were last spotted in Prague.
 My Windows laptop refused to boot into Windows. The ominous error message was:
My Windows laptop refused to boot into Windows. The ominous error message was:
 Developers often ask in forums how they can get their software into retail. I think a more relevant question is – would you want to? Seeing your software for sale on the shelves of your local store must be a great ego boost. But the realities of selling your software through retail are very different to selling online. In the early days of
Developers often ask in forums how they can get their software into retail. I think a more relevant question is – would you want to? Seeing your software for sale on the shelves of your local store must be a great ego boost. But the realities of selling your software through retail are very different to selling online. In the early days of 
 I have have heard plenty of people saying that desktop software is dead and that all future development will be done for the web. From my perspective, as both a buyer and seller of software, I think they are wrong. In fact, of the thousands of pounds I have spent on software in the last three years, I would guess that well over 90% of it was spent on software that runs outside the browser. The capabilities of web based applications have improved a lot in recent years, but they still have a long way to go to match a custom built native application once you move beyond
I have have heard plenty of people saying that desktop software is dead and that all future development will be done for the web. From my perspective, as both a buyer and seller of software, I think they are wrong. In fact, of the thousands of pounds I have spent on software in the last three years, I would guess that well over 90% of it was spent on software that runs outside the browser. The capabilities of web based applications have improved a lot in recent years, but they still have a long way to go to match a custom built native application once you move beyond  There are a few certainties in life: death, taxes and harddisk failure. I have no less than 6 failed harddisks sitting here on my desk patiently awaiting their appointment with Mr Lump Hammer. 2 Seagates, 3 Maxtors and 1 Western Digital. This equates to roughly one disk failure per year. Perhaps this is not suprising given that I have about 9 working harddisks at the moment spread across various machines. Given the incredible tolerances to which harddisks are manfactured, perhaps it is a miracle harddisks work at all.
There are a few certainties in life: death, taxes and harddisk failure. I have no less than 6 failed harddisks sitting here on my desk patiently awaiting their appointment with Mr Lump Hammer. 2 Seagates, 3 Maxtors and 1 Western Digital. This equates to roughly one disk failure per year. Perhaps this is not suprising given that I have about 9 working harddisks at the moment spread across various machines. Given the incredible tolerances to which harddisks are manfactured, perhaps it is a miracle harddisks work at all.
 We all like to think that our software is easy to use. But is it really? How do you know? Have you ever watched anyone use it? When I asked this questions to a room full of developers last year I was surprised at how many hadn’t.
We all like to think that our software is easy to use. But is it really? How do you know? Have you ever watched anyone use it? When I asked this questions to a room full of developers last year I was surprised at how many hadn’t.
 One of the keys to success in Google Adwords (and other pay per click services) is to write good ad copy. This isn’t easy as the ads have a very restrictive format, reminiscent of a haiku:
One of the keys to success in Google Adwords (and other pay per click services) is to write good ad copy. This isn’t easy as the ads have a very restrictive format, reminiscent of a haiku: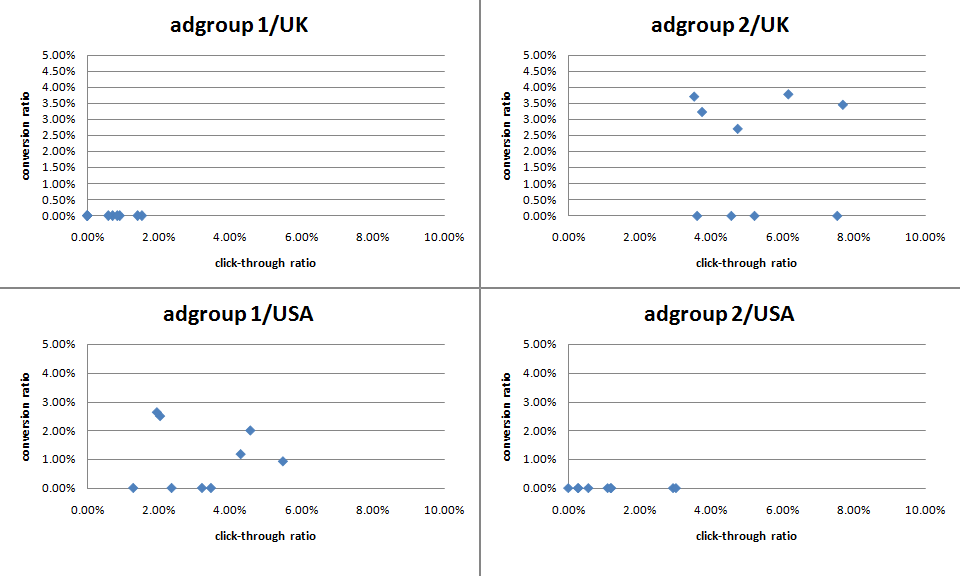
 When I first released
When I first released