 ‘Defence in depth’ is a military strategy where the attacker is allowed to penetrate the defender’s lines, but is then gradually worn down by successive layers of defences. This strategy was famously used by the Soviet Army to halt the German blitzkrieg at the battle of Kursk, using a vast defensive network including trenches, minefields and gun emplacements. Defence in depth also has parallels in non-military applications. I use a defence in depth approach to detect bugs in my code. A bug has to pass through multiple layers of defences undetected before it can cause problems for my customers.
‘Defence in depth’ is a military strategy where the attacker is allowed to penetrate the defender’s lines, but is then gradually worn down by successive layers of defences. This strategy was famously used by the Soviet Army to halt the German blitzkrieg at the battle of Kursk, using a vast defensive network including trenches, minefields and gun emplacements. Defence in depth also has parallels in non-military applications. I use a defence in depth approach to detect bugs in my code. A bug has to pass through multiple layers of defences undetected before it can cause problems for my customers.
Layer 1: Compiler warnings
Compiler warnings can help to spot many potential bugs. Crank your compiler warnings up to maximum sensitivity to get the most benefit.
Layer 2: Static analysis
Static analysis takes over where compiler warnings leave off, examining code in great detail looking for potential errors. An example static analyser is Gimpel PC-Lint for C and C++. PC-Lint performs hundreds of checks for known issues in C/C++ code. The flip side of it’s thoroughness is that it can be difficult to spot real issues amongst the vast numbers of warnings and it can take some time to fine-tune the checking to a useful level.
Layer 3: Code review
A fresh set of eyes looking at your code will often spot problems that you didn’t see. There are various ways to go about this, including formal Fagan inspections, Extreme Programming style pair programming and informal reviews. There is quite a lot of documented evidence to suggest that this is one of the most effective ways to find bugs. It is also an excellent way to mentor less experienced programmers. But it is time consuming and can be hard on the ego of the person being reviewed. Also it isn’t really an option for solo developers
Layer 4: Self-checking
Of the vast space of states that a program can occupy, usually only a minority will be valid. E.g. it might makes no sense to set a zero or negative radius for a circle. We can check for invalid states in C/C++ with an assert() macro:
class Circle
{
public:
void setRadius( double radius );
private:
double m_radius;
}
void Circle::setRadius( double radius )
{
assert( radius > 0.0 );
m_radius = radius;
}
The program will now halt with a warning message if the radius is set inappropriately. This can be very helpful for finding bugs during testing. Assertions can also be useful for setting pre-conditions and post-conditions:
void List::remove( Item* i )
{
assert( contains( i ) );
...
assert( !contains( i ) );
}
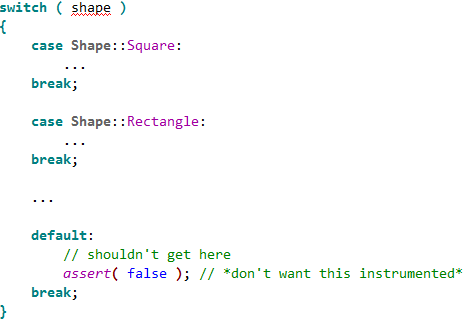
Or detecting when an unexpected branch is executed:
switch ( shape )
{
case Shape::Square:
...
break;
case Shape::Rectangle:
...
break;
case Shape::Circle:
...
break;
case Shape::Ellipse:
...
break;
default:
assert( false ); // shouldn't get here
break;
}
Assertions are not compiled into release versions of the software, which means they don’t incur any overhead in production code. But this also means:
- Assertions are not a substitute for proper error handling. They should only be used to check for states that should never occur, regardless of the program input.
- Calls to an assert() must not change the program state, or the debug and release versions will behave differently.
Different languages have different approaches, for example pre and post conditions are built into the Eiffel language.
Layer 5: Dynamic analysis
Dynamic checking usually involves automatically instrumenting the code in some way so that it’s runtime behaviour can be checked for potential problems such as: array bound violations, reading memory that hasn’t be written to and memory leaks. An example dynamic analyser is the excellent and free Valgrind for Linux. There are a few dynamic analysers for Windows, but they tend to be expensive. The only one I have tried in the last few years was Purify and it was flaky (do IBM/Rational actually use their own tools?).
Layer 6: Unit testing
Unit testing requires the creation of a test harness to execute various tests on a small unit of code (typically a class or function) and flag any errors. Ideally the unit tests should then be executed every time you make a change to the code. You can write your own test harnesses from scratch, but it probably makes more sense to use one of the existing frameworks, such as: NUnit (.NET), JUnit (Java), QUnit (Qt) etc.
According to the Test Driven Development approach you should write your unit tests before you write the code. This makes a lot of sense, but requires discipline.
Layer 7: Integration testing
Integration testing involves testing that different modules of the system work correctly together, particularly the interfaces between your code and hardware or third party libraries.
Layer 8: System testing
System testing is testing the system in it’s entirety, as delivered to the end-user. System testing can be done manually or automatically, using a test scripting tool.
Unit, integration and system testing should ideally be done using a coverage tool such as Coverage Validator to check that the testing is sufficiently thorough.
Layer 9: Regression testing
Regression testing involves running a series of tests and comparing the results to the same input data run on the previous release of the system. Any differences may be the result of bugs introduced since the last release. Regression testing works particularly well on systems that take a single input file and produce a single output file – the output file can just be diff’ed against the previous output.
Layer 10: Third party testing
Different users have different patterns of usage. You might prefer drag and drop, someone else might use right-click a lot and yet another person might prefer keyboard accelerators. So it would be unwise to release a system that has only ever been tested by the developer. Furthermore, the developer inevitably makes all sorts of assumptions about how the software will be used. Some of those assumptions will almost certainly be wrong.
There are a number of companies that can be paid by the day to do third party testing. I have used softwareexaminer.com in the past with some success.
Layer 11: Beta testing
End-user systems can vary in processor speed, memory, screen resolution, video card, font size, language choice, operating system version/update level and installed software. So it is necessary to test your software on a representative range of supported hardware + operating system + installed software. Typically this is done by recruiting users who are keen to try out new features, for example through a newsletter. Unfortunately it isn’t always easy to get good feedback from beta testers.
Layer 12: Crash reporting
If each of the above 11 layers of defence catches 50% of the bugs missed by the previous layer, we would expect only 1 bug in 2,048 to make it into production code undetected. Assuming your coding isn’t spectacularly sloppy in the first place, you should end up with very few bugs in your production code. But, inevitably, some will still slip through. You can catch the ones that crash your software with built-in crash reporting. This is less than ideal for the person whose software crashed. But it allows you to get detailed feedback on crashes and consequently get fixes out much faster.
I rolled my own crash reporting for Windows and MacOSX. On Windows the magic function call is SetUnhandledExceptionFilter. You can also sign up to the Windows Winqual program to receive crash reports via Windows’ own crash reporting. But, after my deeply demoralising encounter with Winqual as part of getting the “works with Vista” logo, I would rather take dance lessons from Steve Ballmer.
Test what you ship, ship what you test
A change of a single byte in your binaries could be the difference between a solid release and a release with a showstopper bug. Consequently you should only ship the binaries you have tested. Don’t ship the release version after only having tested the debug version and don’t ship your software after a bug fix without re-doing the QA, no matter how ‘trivial’ the fix. Sometimes it is better to ship with minor (but known) bugs than to try to fix these bugs and risk introducing new (and potentially much worse) bugs.
Cross-platform development
I find that shipping my software on Windows and MacOSX from a single code base has advantages for QA.
- different tools with different strengths are available on each platform
- the Gnu C++ compiler may warn about issues that the Visual Studio C++ compiler doesn’t (and vice versa)
- a memory error that is intermittent and hard to track down on Windows might be much easier to find on MacOSX (and vice versa)
Conclusion
For the best results you need your layers of checks to be part of your day-to-day development, not something you do just before a release. This is best done by automating them as much as possible, e.g.:
- setting the compiler to treat warnings as errors
- performing static analysis and unit tests on code check-in
- running regression tests on the latest version of the code every night
Also you should design your software in such a way that it is easy to test. E.g. building in log file output can make it much easier to perform regression tests.
Defence in depth can find a high percentage of bugs. But obviously the more bugs you start with the more bugs that will end up in your code. So it doesn’t remove the need for good coding practices. Quality can’t be ‘tested in’ to code afterwards.
I have used all 12 layers of defence above at some point in my career. Currently I am not using static analysis (I must update that PC-Lint licence), code review (I am a solo developer) and dynamic analysis (I don’t currently have a dynamic analyser for Windows or MacOSX). I could also do better on unit testing. But according to my crash reporting, the latest version of PerfectTablePlan has crashed just three times in the last 5000+ downloads (the same bug each time, somewhere deep down in the Qt print engine). Not all customer click the ‘Submit’ button to send the crash reports and crashes aren’t the only type of bug, but I think this is indicative of a good level of quality. It is probably a lot better than most of the other consumer software my customers use[1]. Assuming the crash reporting isn’t buggy, of course…
[1]Windows Explorer and Microsoft Office crash on a daily basis on my current machine.






 I will be tearing myself away from my computer to attend the ACCU conference in Oxford on Thursday 3rd and Friday 4th April (including the dinner on the Friday). There is an
I will be tearing myself away from my computer to attend the ACCU conference in Oxford on Thursday 3rd and Friday 4th April (including the dinner on the Friday). There is an  I have have heard plenty of people saying that desktop software is dead and that all future development will be done for the web. From my perspective, as both a buyer and seller of software, I think they are wrong. In fact, of the thousands of pounds I have spent on software in the last three years, I would guess that well over 90% of it was spent on software that runs outside the browser. The capabilities of web based applications have improved a lot in recent years, but they still have a long way to go to match a custom built native application once you move beyond
I have have heard plenty of people saying that desktop software is dead and that all future development will be done for the web. From my perspective, as both a buyer and seller of software, I think they are wrong. In fact, of the thousands of pounds I have spent on software in the last three years, I would guess that well over 90% of it was spent on software that runs outside the browser. The capabilities of web based applications have improved a lot in recent years, but they still have a long way to go to match a custom built native application once you move beyond  The sink is full of washing, I am wearing odd socks and I haven’t been out of the house in days. It must be time to put out that new release. But how can I be sure my testing hasn’t missed a hideously embarrassing bug? Maybe I introduced a major bug when I made that ‘cosmetic’ change at 2am?
The sink is full of washing, I am wearing odd socks and I haven’t been out of the house in days. It must be time to put out that new release. But how can I be sure my testing hasn’t missed a hideously embarrassing bug? Maybe I introduced a major bug when I made that ‘cosmetic’ change at 2am?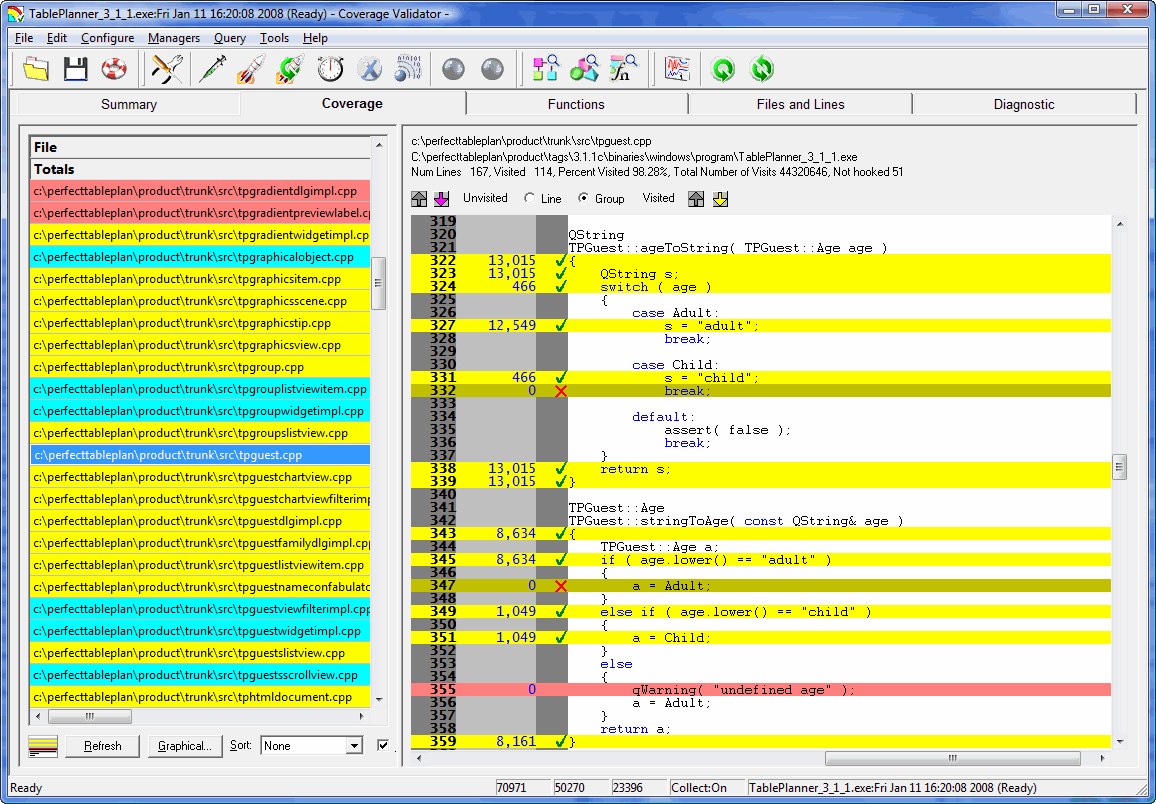


{kind=link}