
 Developers often ask in forums how they can get their software into retail. I think a more relevant question is – would you want to? Seeing your software for sale on the shelves of your local store must be a great ego boost. But the realities of selling your software through retail are very different to selling online. In the early days of Perfect Table Plan I talked to some department stores and a publisher about selling through retail. I was quite shocked by how low the margins were, especially compared with the huge margin for online sales. I didn’t think I was going to make enough money to even cover a decent level of support. So I walked away at an early stage of negotiations.
Developers often ask in forums how they can get their software into retail. I think a more relevant question is – would you want to? Seeing your software for sale on the shelves of your local store must be a great ego boost. But the realities of selling your software through retail are very different to selling online. In the early days of Perfect Table Plan I talked to some department stores and a publisher about selling through retail. I was quite shocked by how low the margins were, especially compared with the huge margin for online sales. I didn’t think I was going to make enough money to even cover a decent level of support. So I walked away at an early stage of negotiations.
The more I have found out about retail since, the worse it sounds. Running a chain of shops is an expensive business and they are going to want take a very large slice of your cake. The various middlemen are also going to take big slices. Because they can. By the time they have all had their slices there won’t be much left of your original cake. That may be OK if the cake (sales volume) is large enough. But it is certainly not something to enter into lightly. Obviously some companies make very good money selling through retail, but I think these are mostly large companies with large budgets and high volume products. Retail is a lot less attractive for small independents and microISVs such as myself.
But software retail isn’t an area I claim to be knowledgeable about. I just know enough to know that it isn’t for me, at least not for the foreseeable future (never say never). So when I spotted a great post on the ASP forums about selling through retail, I asked the author, Al Harberg, if I could republish it here. I thought it was too useful to be hidden away on a private forum. He graciously agreed. If you decide to pursue retail I hope it will help you to go into it with your eyes open. Over to Al.
In the 24 years that I’ve been writing press releases and sending them to the editors, more than 90 percent of my customers have been offering software applications on a try-before-you-buy basis. In addition, quite a few of them have ventured into the traditional retail distribution channel, boxed their software, and offered it for sale in stores. This is a summary of their retail store experiences.
While the numbers vary greatly, a software arrangement would have revenues split roughly:
- Retail store – 50 percent
- Distributor – 10 percent
- Publisher – 30 to 35 percent
- Developer – 5 to 10 percent
Retail stores don’t buy software from developers or from publishers. They only buy from distributors.
The developer would be paid by the publisher. In the developer’s contract, the developer’s percentage would be stated as a percentage of the price that the publisher sells the software to the distributor, and not as a percentage of the retail store’s price.
The publishers take most of the risks. They pay the $30,000(US) or so that it currently takes to get a product into the channel. This includes the price of printing and boxing the product, and the price of launching an initial marketing campaign that would convince the other parties that you’re serious about selling your app.
If your software doesn’t sell, the retail stores ship the boxes back to the distributor. The distributor will try to move the boxes to other dealers or value-added resellers (VARs). But if they can’t sell the product, the distributors ship the cartons back to the publisher.
While stores and distributors place their time at risk, they never risk many of their dollars. They don’t pay the publisher a penny until the software is sold to consumers (and, depending upon the stores’ return policies, until the product is permanently sold to consumers – you don’t make any money on software that is returned to the store, even though the box has been opened, and is not in good enough condition to sell again).
The developer gets paid two or three months after the consumer makes the retail purchase. Sometimes longer. Sometimes never. If you’re dealing with a reputable publisher, and they’re dealing with a major distributor, you’ll probably be treated fairly. But most boilerplate contracts have “after expenses” clauses that protect the other guys. You need to hire an attorney to negotiate the contract, or you’re not going to be happy with the results. And your contract should include an up-front payment that covers the publisher’s projection of several months’ income, because this up-front payment might well be the only money that you’re going to ever see from this arrangement.
Retail stores’ greatest asset is their shelf space. They won’t stock a product unless there is demand for it. You can tell them the most convincing story in the world about how your software will set a new paradigm, and be a runaway bestseller. But if the store doesn’t have customers asking for the app, they’re not going to clutter their most precious asset with an unknown program.
It’s a tough market. It’s all about sales. And if there is no demand for your software, you’re not going to get either a distributor or a store interested in stocking your application. These folks are not interested in theoretical demand. They’re interested in the number of people who come into a retail store and ask for the product.
To convince these folks that you’re serious, the software publisher has to show a potential distributor that they have a significant advertising campaign in place that will attract prospects and create demand, and that they have a press release campaign planned that will generate buzz in the computer press.
Many small software developers have found that the retail experience didn’t work for them. They’re back to selling exclusively online. Some have contracted with publishers who sell software primarily or exclusively online. Despite all of the uncertainties of selling software online, wrestling with the retail channel has even more unknowns.
Al Harberg
Al Harberg has been helping software developers write press releases and send them to the editors since 1984. You can visit his website at www.dpdirectory.com.

 I have have heard plenty of people saying that desktop software is dead and that all future development will be done for the web. From my perspective, as both a buyer and seller of software, I think they are wrong. In fact, of the thousands of pounds I have spent on software in the last three years, I would guess that well over 90% of it was spent on software that runs outside the browser. The capabilities of web based applications have improved a lot in recent years, but they still have a long way to go to match a custom built native application once you move beyond
I have have heard plenty of people saying that desktop software is dead and that all future development will be done for the web. From my perspective, as both a buyer and seller of software, I think they are wrong. In fact, of the thousands of pounds I have spent on software in the last three years, I would guess that well over 90% of it was spent on software that runs outside the browser. The capabilities of web based applications have improved a lot in recent years, but they still have a long way to go to match a custom built native application once you move beyond  I am offering £100 off my daily consulting fee until the end of March. Could you use an experienced and objective review of your strategy, marketing and product? When you have been eating, sleeping and breathing your business it can be difficult to ‘see the wood for the trees’ and a fresh perspective can be a huge help.
I am offering £100 off my daily consulting fee until the end of March. Could you use an experienced and objective review of your strategy, marketing and product? When you have been eating, sleeping and breathing your business it can be difficult to ‘see the wood for the trees’ and a fresh perspective can be a huge help. 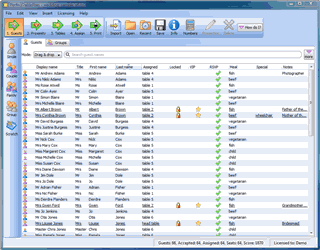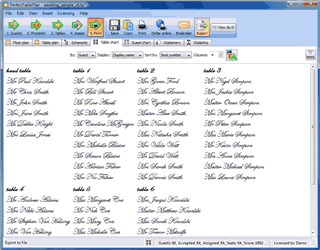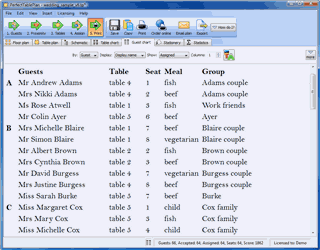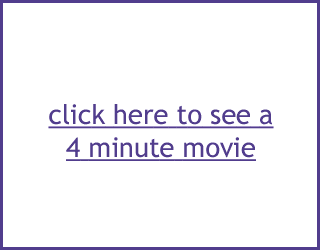
 The sink is full of washing, I am wearing odd socks and I haven’t been out of the house in days. It must be time to put out that new release. But how can I be sure my testing hasn’t missed a hideously embarrassing bug? Maybe I introduced a major bug when I made that ‘cosmetic’ change at 2am?
The sink is full of washing, I am wearing odd socks and I haven’t been out of the house in days. It must be time to put out that new release. But how can I be sure my testing hasn’t missed a hideously embarrassing bug? Maybe I introduced a major bug when I made that ‘cosmetic’ change at 2am?
 If people buy your software in bulk they expect to get a discount. But how much of a discount should you give them? A simple formula I have seen used is:
If people buy your software in bulk they expect to get a discount. But how much of a discount should you give them? A simple formula I have seen used is:
