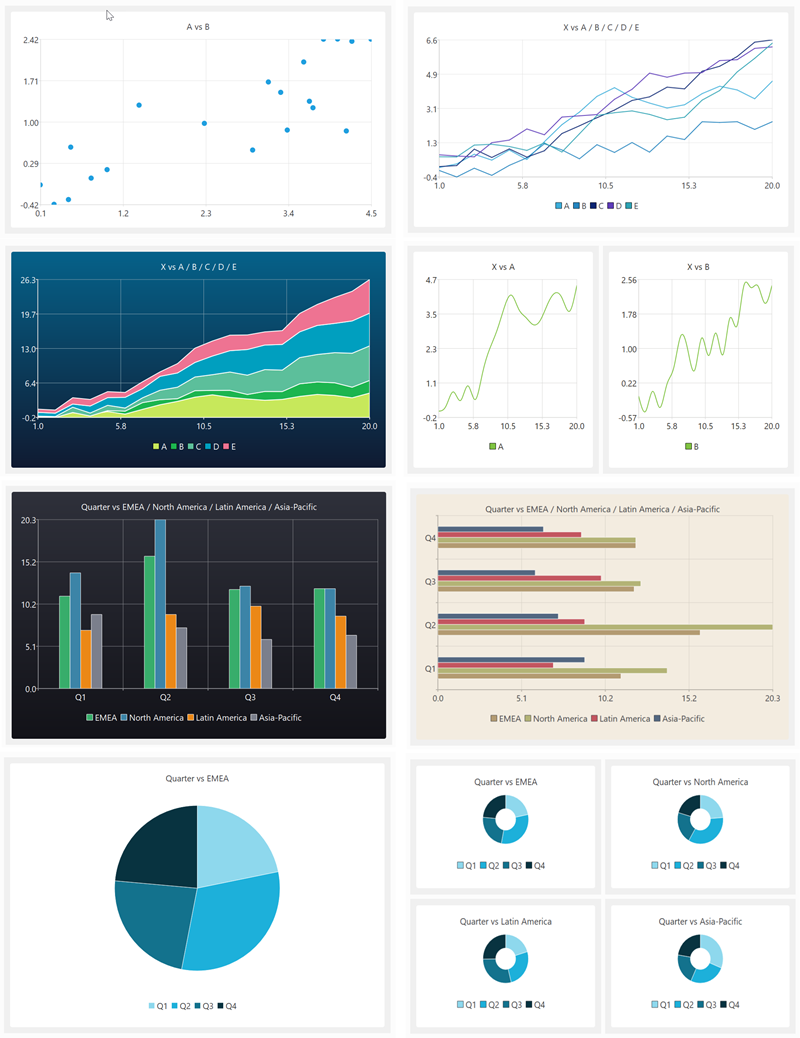
My data wrangling product, Easy Data Transform, got a major upgrade yesterday, with the addition of data visualization capabilities. Here are some examples of what it can produce in a few clicks:
You can see this new visualization feature in action in the video below:
(Likes and subscribes help me with the YouTube algorithm and are much appreciated)
Human brains are highly developed for visual processing. But data is often messy and in the wrong form for visualization. So data wrangling and visualization, tightly integrated together, is a powerful combination. It was a lot of work, but it makes Easy Data Transform a much more complete, end-to-end, solution. No more pasting data into Excel to get a chart!
At the same time, I have segmented Easy Data Transform into 2 products: Easy Data Transform Core Edition (data wrangling, one-time fee $99) and Easy Data Transform Advanced Edition (data wrangling+visualization, one-time fee $198). The Advanced Edition is a paid upgrade from the original product. Optional, of course. I sweetened the deal with a time-limited discount for existing customers who want to upgrade to Advanced Edition. The response from Easy Data Transform customers has been very positive.
Have you got some messy data, you want to turn into insights? Why not give Easy Data Transform Advanced Edition a try? It:
Runs natively on Windows and Mac.
Is drag and drop (no syntax to remember).
Does not store your precious data on someone else’s server.
Is deterministic and will not hallucinate!
Can process millions of rows in seconds.
Can create re-usable templates for repeatable processes.
You can download a free trial here. And you can get 15% off Easy Data Transform Advanced Edition until 17-Jul-2026 using this discount link.
I released Easy Data Transform v2 today. After no fewer than 80 (!) v1 production releases since 2019, this is the first paid upgrade.
Major improvements include:
Schema versioning, so you can automatically handle changes to the column structure of an input (e.g. additional or missing columns).
A new Verify transform so you can check a dataset has the expected values.
Currently there are 48 different verification checks you can make:
At least 1 non-empty value
Contains
Don’t allow listed values
Ends with
Integer except listed special value(s)
Is local file
Is local folder
Is lower case
Is sentence case
Is title case
Is upper case
Is valid EAN13
Is valid email
Is valid telephone number
Is valid UPC-A
Match column name
Matches regular expression
Maximum characters
Maximum number of columns
Maximum number of rows
Maximum value
Minimum characters
Minimum number of columns
Minimum number of rows
Minimum value
No blank values
No carriage returns
No currency
No digits
No double spaces
No duplicate column names
No duplicate values
No empty rows
No empty values
No gaps in values
No leading or trailing whitespace
No line feeds
No non-ASCII
No non-printable
No punctuation
No symbols
No Tab characters
No whitespace
Numeric except listed special value(s)
Only allow listed values
Require listed values
Starts with
Valid date in format
You can see any fails visually, with colour coding by severity:
Side-by-side comparison of dataset headers:
Side-by-side comparison of dataset data values:
Lots of extra matching options for the Lookup transform:
Allowing you to do exotic lookups such as:
Plus lots of other changes.
In v1 there were issues related to how column-related changes cascaded through the system. This was the hardest thing to get right, and it took a fairly big redesign to fix all the issues. As a bonus, you can now disconnect and reconnect nodes, and it remembers all the column-based options (within certain limits). These changes make Easy Data Transform feel much more robust to use, as you can now make lots of changes without worrying too much about breaking things further downstream.
Easy Data Transform now supports:
9 input formats (including various CSV variants, Excel, XML and JSON)
66 different data transforms (such as Join, Filter, Pivot, Sample and Lookup)
11 output formats (including various CSV variants, Excel, XML and JSON)
56 text encodings
This allows you to snap together a sequence of nodes like Lego, to very quickly transform or analyse your data. Unlike a code-based approach (such as R or Python) or a command line tool, it is extremely visual, with pretty-much instant feedback every time you make a change. Plus, no pesky syntax to remember.
Eating my own dogfood, using Easy Data Transform to create an email marketing campaign from various disparate data sources (mailing lists, licence key databases etc).
Easy Data Transform is all written in C++ with memory compression and reference counting, so it is fast and memory efficient and can handle multi-million row datasets with no problem.
While many of my competitors are transitioning to the web, Easy Data Transform remains a local tool for Windows and Mac. This has several major advantages:
Your sensitive data stays on your computer.
Less latency.
I don’t have to pay your compute and bandwidth costs, which means I can charge an affordable one-time fee for a perpetual licence.
I think privacy is only going to become ever more of a concern as rampaging AIs try to scrape every single piece of data they can find.
Usage-based fees for online data tools are no small matter. For a range of usage fee horror stories, such as enabling debug logging in a large production ETL pipeline resulting in $100k of extra costs in a week, see this Reddit post. Some of my customers have processed more than a billion rows in Easy Data Transform. Not bad for $99!
It has been a lot of hard work, but I am please with how far Easy Data Transform has come. I think Easy Data Transform is now a comprehensive, fast and robust tool for file-based data wrangling. If you have some data to wrangle, give it a try! It is only $99+tax ($40+tax if you are upgrading from v1) and there is a fully functional, 7 day free trial here:
I am very grateful to my customers, who have been a big help in providing feedback. This has improved the product no end. Many heads are better than one!
The next big step is going to be adding the ability to talk directly to databases, REST APIs and other data sources. I also hope at some point to add the ability to visualize data using graphs and charts. Watch this space!
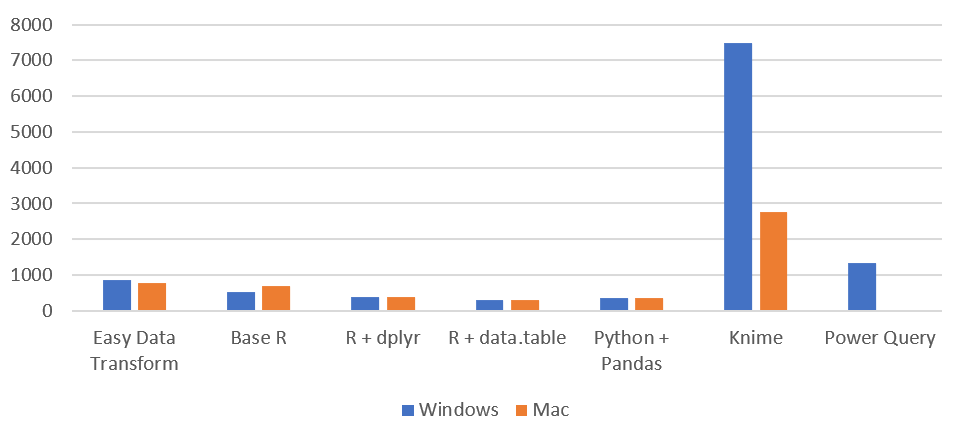
I have been gradually improving my data wrangling tool, Easy Data Transform, putting out 70 public releases since 2019. While the product’s emphasis is on ease of use, rather than pure performance, I have been trying to make it fast as well, so it can cope with the multi-million row datasets customers like to throw at it. To see how I was doing, I did a simple benchmark of the most recent version of Easy Data Transform (v1.37.0) against several other desktop data wrangling tools. The benchmark did a read, sort, join and write of a 1 million row CSV file. I did the benchmarking on my Windows development PC and my Mac M1 laptop.
Here is an overview of the results:
Time by task (seconds), on Windows without Power Query (smaller is better):
I have left Excel Power Query off this graph, as it is so slow you can hardly see the other bars when it is included!
Time by task (seconds) on Mac (smaller is better):
Memory usage (MB), Windows vs Mac (smaller is better):
So Easy Data Transform is nearly as fast as it’s nearest competitor, Knime, on Windows and a fair bit faster on an M1 Mac. It is also uses a lot less memory than Knime. However we have got some way to go to catch up with the Pandas library for Python and the data.table package for R, when it comes to raw performance. Hopefully I can get nearer to their performance in time. I was forbidden from including benchmarks for Tableau Prep and Alteryx by their licensing terms, which seems unnecessarily restrictive.
Looking at just the Easy Data Transform results, it is interesting to notice that a newish Macbook Air M1 laptop is significantly faster than a desktop AMD Ryzen 7 desktop PC from a few years ago.
I have been working hard on Easy Data Transform. The last few releases have included:
a 64 bit version for Windows
JSON, XML and vCard format input
output of nested JSON and XML
a batch processing mode
command line arguments
keyboard shortcuts
various improvements to transforms
Plus lots of other improvements.
The installer now includes 32 and 64 bit version of Easy Data Transform for Windows and installs the one appropriate to your operating sytem. This is pretty easy to with the Inno Setup installer. You just need to use Check: Is64BitInstallMode, for example:
But it does pretty much double the size of the installer (from 25MB to 47MB in my case).
The 32 bit version is restricted to addressing 4GB of memory. In practise, this means you may run out of memory if you get much above a million data values. The 64 bit version is able to address as much memory as your system can provide. So datasets with tens or hundreds of millions of values are now within reach.
I have kept the 32 bit version for compatibility reasons. But data on the percentage of customers still using 32 bit Windows is surprisingly hard to come by. Some figures I have seen suggest <5%. So I will probably drop 32 bit Windows support at some point. Apple, being Apple, made the transition to a 64 bit OS much more aggressively and so the Mac version of Easy Data Transform has always been 64 bit only.
I have also been doing some benchmarking and Easy Data Transform is fast. On my development PC it can perform an inner join of 2 datasets of 900 thousand rows x 14 columns in 5 seconds. The same operation on the same machine in Excel Power Query took 4 minutes 20 seconds. So Easy Data Transform is some 52 times faster than Excel Power Query. Easy Data Transform is written in C++ with reference counting and hashing for performance, but I am surprised by just how much faster it is.
The Excel Power Query user interface also seems very clunky by comparison. The process to join two CSV files is:
Start Excel.
Start Power Query.
Load the two data files into Excel power query.
Choose the key columns.
Choose merge.
Choose inner join. Wait 4 minutes 20 seconds.
Load the results back into Excel. Wait several more minutes.