I have been working hard on Easy Data Transform. The last few releases have included:
- a 64 bit version for Windows
- JSON, XML and vCard format input
- output of nested JSON and XML
- a batch processing mode
- command line arguments
- keyboard shortcuts
- various improvements to transforms
Plus lots of other improvements.
The installer now includes 32 and 64 bit version of Easy Data Transform for Windows and installs the one appropriate to your operating sytem. This is pretty easy to with the Inno Setup installer. You just need to use Check: Is64BitInstallMode, for example:
[Files]
Source: "..\binaries\windows\program\{#MyAppExeName}"; DestDir: "{app}"; Flags: ignoreversion; Check: not Is64BitInstallMode
Source: "..\binaries\windows\program64\{#MyAppExeName}"; DestDir: "{app}"; Flags: ignoreversion; Check: Is64BitInstallMode
But it does pretty much double the size of the installer (from 25MB to 47MB in my case).
The 32 bit version is restricted to addressing 4GB of memory. In practise, this means you may run out of memory if you get much above a million data values. The 64 bit version is able to address as much memory as your system can provide. So datasets with tens or hundreds of millions of values are now within reach.
I have kept the 32 bit version for compatibility reasons. But data on the percentage of customers still using 32 bit Windows is surprisingly hard to come by. Some figures I have seen suggest <5%. So I will probably drop 32 bit Windows support at some point. Apple, being Apple, made the transition to a 64 bit OS much more aggressively and so the Mac version of Easy Data Transform has always been 64 bit only.
I have also been doing some benchmarking and Easy Data Transform is fast. On my development PC it can perform an inner join of 2 datasets of 900 thousand rows x 14 columns in 5 seconds. The same operation on the same machine in Excel Power Query took 4 minutes 20 seconds. So Easy Data Transform is some 52 times faster than Excel Power Query. Easy Data Transform is written in C++ with reference counting and hashing for performance, but I am surprised by just how much faster it is.
The Excel Power Query user interface also seems very clunky by comparison. The process to join two CSV files is:
- Start Excel.
- Start Power Query.
- Load the two data files into Excel power query.
- Choose the key columns.
- Choose merge.
- Choose inner join. Wait 4 minutes 20 seconds.
- Load the results back into Excel. Wait several more minutes.
- Save to a .csv file.
- Total time: ~600 seconds
Whereas in Easy Data Transform you just:
- Start Easy Data Transform.
- Drag the 2 files onto the center pane.
- Click ‘join’.
- Select the key columns. Wait 5 seconds.
- Click ‘To file’ and save to a .csv file.
- Total time: ~30 seconds
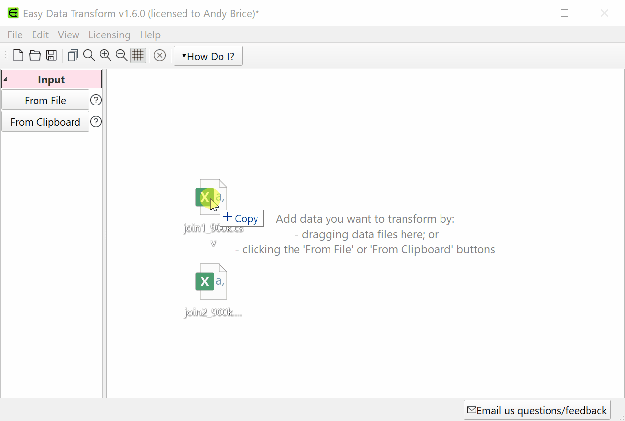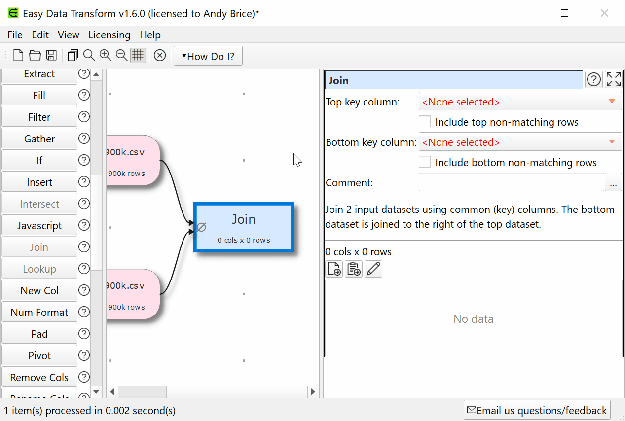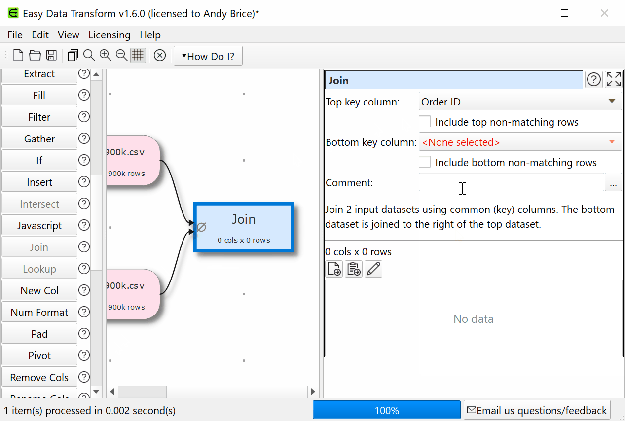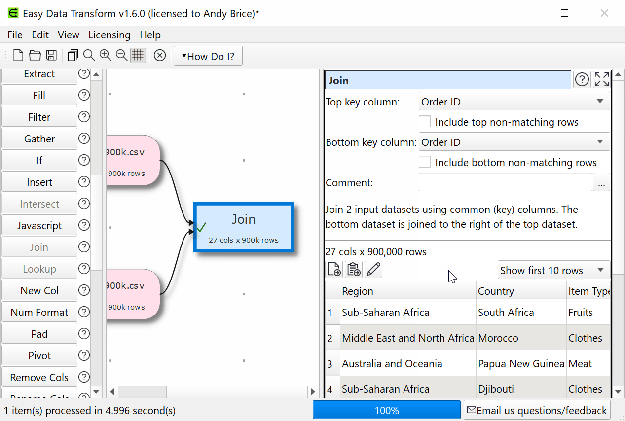
If you have some data to transform, clean or analyze please give Easy Data Transform a try. There is a fully functional free trial. Email me if you have any questions.


 There is a story that a president of a pet food company ate some of his own dog food, to show how good it was. I’m not sure how tasty dog food really needs to be, given that dogs are happy to lick their own backsides. But his commitment is admirable. The least we can do as software developers is to use our own software as much as possible. After all, if you don’t use it, how can you expect anyone else to?
There is a story that a president of a pet food company ate some of his own dog food, to show how good it was. I’m not sure how tasty dog food really needs to be, given that dogs are happy to lick their own backsides. But his commitment is admirable. The least we can do as software developers is to use our own software as much as possible. After all, if you don’t use it, how can you expect anyone else to?