The application icon for my data wrangling software looks like this on a Mac up to macOS 15.x:
However, Apple has once again nuked everything from orbit. Now it looks like this in macOS 26 Tahoe when the application is inactive or if you choose any Icon & widget style apart from Default:
Thanks Apple. It is such a joy to develop for Mac.
With some help from a designer and hours of going around in circles, I have finally managed to fix things to support the new ‘liquid glass’ look. This is how it should look in the next release, depending on the setting in Appearance>Icon & widget style:
Default
Dark
Clear/Light
Clear/Dark
Tinted
I’m not convinced it is an improvement in terms of usability. But, at least my app icon doesn’t look like shit.
What you need to know
The new macOS 26 icon format is .icon. It is a folder full of various resources and is totally different to the old .icns format.
The .icon file can be created by Apple Icon Composer. I used a freelancer on Fiverr who did a good job of converting my existing vector artwork and was very cheap. The .icon file should contain a maximum of 4 groups (which seem to be like layers) other it won’t compile to a resource properly.
Note that macOS hide the extension of .icon folders by default, which was a source of some confusion.
The .icon file then has to be processed into an Assets.car file using actool. For example:
xcrun actool application.icon --compile ./icons/macosx --output-format human-readable-text --notices --warnings --errors --output-partial-info-plist temp.plist --app-icon Icon --include-all-app-icons --enable-on-demand-resources NO --development-region en --target-device mac --minimum-deployment-target 26.0 --platform macosx
You will need to change the bold parts above, as appropriate.
I had to update my Mac laptop to macOS 26, Xcode 26 and the macOS 26 SDK for the above to work.
You can check the Assets.car file using assetutil to create a .json file listing the contents:
You will need to change the bold part above, as appropriate. I believe the string value if based on the file stem of the original .icon file. But I’m not 100% sure about that. Look at the .json file produced by assetutil for clues. Mine contained this:
The temp.plist file generated by actool is apparently supposed to give you a .plist file that refers to the icon resource. It didn’t and was completely useless.
Then place both Assets.car and your old .icns file in the Resource folder of your application (before you sign it). That way it should look ok on both macOS 26 and earlier OSes.
If you develop using XCode, it will probably do some of the above for you. I develop in C++/Qt using Qt Creator, so I had to do it all manually.
I was able to generate the Assets.car on macOS 26 and then incorporate it into the build on my macOS 12 development machine.
I hope the above saves someone a few hours. Now I need to repeat the process for PerfectTablePlan.
You might also find this post useful (where I got some of the information):
I am always on the lookout for cost and time effective ways that I can market my software products. Previously, I have had quite a lot of success with Google Adwords Pay Per Click ads. However, the law of shitty clickthroughs means that advertising platforms generally get less and less profitable (for the advertisers) over time. And Google Adwords is a case study of that law in action. As Reddit is a less mature advertising platform, I thought it might still offer opportunities for a decent return. So I decided to experiment with advertising my data munging software, Easy Data Transform, on Reddit.
[By the way, I understand that nobody goes to Reddit because they want to see ads. But commercial products need to market themselves to survive, and Reddit probably wouldn’t exist without ads. Yay capitalism.]
Setup
The basic process to get started with Reddit Ads is:
Sign up for a Reddit Ads account.
Enter your details and credit card number.
Create a campaign.
Create one or more ad groups for your campaign. Choose a bid for each ad group, which countries you want it shown in and who you want it shown to.
Create one or more ads for each group.
Add the Reddit tracking pixel to every page of your website.
Set up conversion goals.
All pretty standard stuff for anyone who has used Google Adwords. The twist with Reddit is that you can advertise to communities (sub-Reddits), rather than based on search keywords. For example, Easy Data Transform is a much better tool for most data wrangling tasks than Excel, so I can bid to show ads targeted at Excel users in communities such as: reddit.com/r/excel/ and reddit.com/r/ExcelTips/.
Like Adwords, there are various ways to bid. I don’t want the advertising platform to set the bid prices for me (because I’m not insane), so I opted for fixed price bids of between $0.20 and $0.40 per click. Some of the ad groups suggested much higher bids than that. For example, the suggested bid for my Excel ad group is $0.79 to $4.79 per click!
However, Easy Data Transform is only a one time payment of $99. Paying more than $0.40 per click is unlikely to be profitable for me, especially when you factor in support costs. So that is the maximum I was prepared to bid. Also, the suggested bids are just the ad platform trying to push up the bid price. Something that anyone who has used Google Adwords will be all too familiar with. I was still able to get clicks, bidding significantly less than the recommended minimum.
I also set a daily maximum for each ad group, just in case I had messed up and added a zero in a bid somewhere.
I created multiple ads for each ad group, with a range of different text and images specific to the communities targeted. Here are some of the ones I ran in the Excel ad group:
I didn’t try to use edgy images or memes, because that isn’t really my style. There is an option to turn comments on below ads. As Reddit users are generally not well-disposed to ads, I didn’t try turning this on.
Based on hard-won experience with Google Adwords, I only set my ads to run in wealthy countries. I also restricted my ads to people on desktop devices as Easy Data Transform only runs on the desktop.
When Easy Data Transform is installed, it opens a page on my website with some instructions. So I used this to set up the Reddit conversion tracking to count the number of times a click ended up with a successful install of either the Windows or Mac version of Easy Data Transform.
I monitored the performance of the ads and disabled those that has poor click through or conversion rates and made variants of the more successful ones. Darwinian evolution for ads. I ended up creating 70 ads across 15 ad groups, targeting 50 communities.
I wasted an hour trying to get Reddit to recognize that I had installed their tracking pixel. But, overall, I found the Reddit Ads relatively simple to setup and monitor. Especially compared to the byzantine monstrosity that Google Adwords has become.
Reddit advertises a deal where you can get $500 of free ads.
But the link was broken when I clicked on it. Someone else I spoke to said they had tried to find out more, but gave up when they found out you had to have a phone call with a sales person at Reddit.
Results
I ran my experiment from 08-Jul-2025 to 31-Jul-2025. These are the stats, according to reddit.
Spend
$851.04
Impressions
490,478
Clicks
3,585
Windows installs
177
Mac installs
63
Total installs
240
Click Through Rate
0.73%
Cost Per Click
$0.24
Click to install conversion rate
6.59%
Cost Per Install
$3.55
I generally reckon that somewhere around 10% of people who install are going on to buy. So $3.55 per install would mean around $35.50 cost per sale, which is reasonable for a $99 sale. So that all looks quite encouraging.
But, comparing the Reddit number to the numbers I get from Google Analytics and my web logs, I think the Reddit numbers are dubious. At best. In a week when Reddit says it sent me 1174 clicks, Google Analytics says I received 590 referrals from Reddit and my web log says I received 639 referrals from Reddit. Some of the difference may be due to comparing sessions with clicks, time zones etc. But it looks fishy.
The discrepancy is even greater if you look at conversions. The total installs per week reported by Google Analytics and my web logs didn’t go up anything like you would expect from looking at the Reddit conversion numbers. If you dig a bit further, you find that Reddit uses ‘modeled conversions‘ to:
“Gain a more complete view of your ads performance with modeled conversions, which leverages machine learning to bridge attribution gaps caused by signal loss.”
Uh huh. Sounds suspiciously like ‘making shit up’.
And then there are the sales. Or lack of. I don’t have detailed tracking of exactly where every sale comes from. But I estimate that my $851 outlay on ads resulted in between $0 and $400 in additional sales. Which is not good, given that I don’t have VC money to burn. Especially when you factor in the time taken to run this experiment.
The top 5 countries for spend were:
Italy
Spain
France
Germany
Singapore
The US only accounted for 0.28% of impressions, 13 clicks and $3.81 in spend. Presumably because the US market is more competitive, and I wasn’t bidding enough to get my ads shown.
You can look at various breakdowns by country, community, device etc. This is helpful. But some of the breakdowns make no sense. For example, it says that 41% of the click throughs from people reading Mac-related communities were from Windows PCs. That sounds very unlikely!
But the worst is still to come. Feast your eyes on this Google Analytics data from my website:
Average engaged time per active user (seconds)
Engaged sessions per active user
Google / organic
33
0.75
Successfulsoftware.net / referral
31
0.74
Youtube.com / referral
27
0.86
Chatgpt.com / referral
24
0.69
Google / CPC
16
0.65
Reddit / referral
8
0.25
8 seconds! That is the mean, not the median. Yikes. And 75% of the sessions didn’t result in any meaningful engagement. This makes me wonder if the majority of the Reddit clicks are accidental.
I had intended to spend $1000 on this experiment, but the results were sufficiently horrible that I stopped before then.
If I had spent a lot of time tweaking the ad images and text, landing pages, communities and countries, then I could probably have improved things a bit. But I doubt I could ever get a worthwhile return on my time and money.
If the lifetime value of a sale is a lot more than $99 for you, or your product is a good fit for Reddit, then Reddit Ads might be worth trying. But be sure not to take any Reddit numbers at face value.
Bearing in mind that I am a developer and NOT A LAWYER, it is my understanding that if:
You host a discussion forum.
and
You, or any of your users, are based in the UK.
Then the UK government considers you subject to the UK Online Safety Act. Even if your forum is about hamsters. Failing to comply could get you a fine of up to £18 million or 10% of the company’s global revenue, whichever is greater.
That got your attention, didn’t it?
How can you be subject to UK law if you don’t have a presence in the UK? Good question. Are they going to extradite you or grab you if you come to the UK on holiday? I have no idea. Isn’t it all a bit over the top for a small customer forum? I think so. What if every country starts trying to apply their laws to citizens in other countries? Bigger yachts for the partners in law companies, I guess.
If you are outside the UK, you will have to make your own decision about whether to care about this law. But I am based in the UK. So I definitely need to care about it – even though my Discourse forum is a highly moderated, technical forum about data cleaning, transformation and analysis, with no porn, violence or gambling content.
There are hundreds of pages of guidance about this new law, which covers massive companies, such as Google and PornHub, as well as my little company. But my understanding is that the minimum a forum owner needs to do is:
Have an online safety policy
Assess the likelihood of children accessing your site
Assess the risk of harmful content
Take appropriate measure based on the above
Regularly update your assessments
Depending on your assessment and the type of content, you may need age verification checks or other measures. I assess that my data wrangling forum is not attractive to children and very unlikely to have harmful content, so I have not gone through the massive ball-ache of adding age verification.
For good measure, I have also disabled the ability of customers to direct message each other. As that is something I can’t moderate and don’t want to be responsible for.
This is 2025, so I generated my online safety policy and assessments with some help from Microsoft CoPilot. Feel free to use them for some inspiration if you need to generate your own policy. But please don’t copy them word-for-word.
Incidentally, generating documents that none of my customers will ever read seems the perfect use case for LLMs.
I really hope I don’t get forced to add age verification. I would rather shut down the forum.
And it only took me 18 years! I know some people wouldn’t get out of bed for 3 million views, but that isn’t going to stop me bragging about it.
I haven’t really done much to promote the blog, apart from occasionally posting links to Hacker News.
The yearly hits have gone down over time. Mostly because I have been writing less often. These days I have 3 products to keep me busy. But also blogs are less of a ‘thing’ than they used to be.
Here are the 20 most visited posts:
Probably the high point for the blog was the software awards scam post getting a mention in the Guardian newspaper.
Power laws are very much in evidence, with the top 1% of the posts accounting for 18% of the hits. I have been consistently wrong in guessing which posts would be popular.
Was all that effort, writing articles worth 35k (of untargetted) clicks throughs to my PerfectTablePlan website? Probably not directly. Even when people did click through to my product websites, the engagement was often very low. But I am guessing that the improved domain authority from links to my seating plan software website has been helpful in improving search rank (see what I did there?). Promoting my products was never the only aim of the blog anyway.
Some posts I have written were mostly notes to my future self. And there have been several cases where Googling for an answer sent me to an article on my own blog that I had fogotten having written.
I have accepted a few guest posts. But I have been extremely picky about which guest posts to accept. I have also turned down plenty of offers for paid links.
Here is where the traffic came from, by source:
I was quite suprised by how much traffic has come from stumbleupon.com.
Digg.com, remember them?
Google completely dominates the search engine results, with Bing managing a pitiful 2.6% of search engine hits. Presumably from people too lazy or ‘non technical’ to change their Windows defaults.
Here is the traffic, by country:
Very little traffic came from Africa, South America or Asia:
Of course, it is hard to know how much of the traffic is humans and how much is bots.
There have been some 37k non-spam comments:
Quite a lot of the comments are responses by me. I have also learnt a lot of useful stuff through feedback on the blog and discussions, when links were posted to places like Hacker News. But the number of comments on the blog has markedly decreased, even taking account of the overall decrease in traffic. On the plus side, I have a lot less comment spam to deal with. It was quite overwhelming at one point. This is a comment from the blog in 2008:
I have given up looking through the spam logs. There is just too much of it and one can only read so many spam comments about Viagra and bestiality without becoming profoundly depressed about the human condition.
Thankfully WordPress seem to have greatly upped their game on spam detection since then.
Here is the top 20 sites where the traffic went:
The ‘social capital’ from the blog has been useful for promoting my consulting services and the training course I ran. Also for promoting various charitable and other causes I felt worthwhile.
I have a vague idea that I might, one day, write a book about starting a small software company. If I do, I will certainly mine the blog for material.
PS/ No, tiresome ‘SEO experts’, I still don’t want to put your boring, crappy guest post ‘articles’ with their dodgy links on my blog. So please don’t waste both our time by asking.
I released version 1 of my table seating planning software, PerfectTablePlan, in February 2005. 20 years ago this month. It was a different world. A world of Windows, shareware and CDs. A lot has changed since then, but PerfectTablePlan is now at version 7 and still going strong.
PerfectTablePlan v1
PerfectTablePlan v7
I have released several other products since then, and done some training and consulting, but PerfectTablePlan remains my most successful product. It’s success is due to a lot of hard work, and a certain amount of dumb luck.
I was getting married and I volunteered to do the seating plan for our wedding reception. It sounded like a relatively straightforward optimization problem, as we only had 60 guests and no family feuds to worry about. But it was surprisingly difficult to get right. I looked around for some software to help me. There were a couple of software packages, but I wasn’t impressed. I could do better myself! So I wrote a (very rough) first version, which I used for our wedding.
Things weren’t going great at my day job, at a small software startup. Maybe I could commercialize my table planner? I was a bit wary, as my potential competitors all seemed rather moribund and I didn’t think I would be able to make a living off it. But I thought I could do everything worth doing in 6-12 months and then start on the next product. Wrong on both counts!
Web-based software was still in its infancy in 2005. So I decided to write it as desktop software using C++ and cross-platform framework Qt, which I had plenty of experience in. Initially, I just released a Windows version. But I later added a Mac version as well. Qt has had its commercial ups and downs in the last 20 years, but it has grown with me and is now very robust, comprehensive and well documented. I think I made a good choice.
I financed PerfectTablePlan out of my own savings and it has been profitable every year since version 1 was launched. I could have taken on employees and grown the business, but I preferred to keep it as a lifestyle business. My wife does the accounts and proof reading and I do nearly everything else, with a bit of help from my accountant, web designers and a few other contractors. I don’t regret that decision. 20 years without meetings, ties or alarm clocks. My son was born 18 months after PerfectTablePlan was launched and it has been great to have the flexibility to be fully present as a Dad.
CDs, remember them? I sent out around 5,000 CDs (with some help from my father), before I stopped shipping CDs in 2016.
During the lifetime of PerfectTablePlan it became clear that things were increasingly moving to the web. But I couldn’t face rewriting PerfectTablePlan from scratch for the web. Javascript. Ugh. Also PerfectTablePlan is quite compute intensive, using a genetic algorithm to generate an automated seating plan and I felt it was better running this on the customer’s local computers than my server. And some of my customers consider their seating plans to be confidential and don’t want to store them on third party servers. So I decided to stick with desktop. But, if I was starting PerfectTablePlan from scratch now, I might make a different decision.
Plenty of strange and wonderful things have happened over the last 20 years, including:
PerfectTablePlan has been used by some very famous organizations for some very famous events (which we mostly don’t have permission to mention). It has seated royalty, celebrities and heads of state.
A mock-up of PerfectTablePlan, including icons I did myself, was used without our permission by Sony in their ‘Big day’ TV comedy series. I threated them with legal action. Years later, I am still awaiting a reply.
I got to grapple with some interesting problems, including the mathematics of large combinatorial problems and elliptical tables. Some customers have seated 4,000 guests and 4000! (4000x3999x3998 .. x 1) is a mind-bogglingly huge number.
A well known wedding magazine ran a promotion with a valid licence key clearly visible in a photograph of a PerfectTablePlan CD. I worked through the night to release a new version of PerfectTablePlan that didn’t work with this key.
I once had to stay up late, in a state of some inebriation, to fix an issue so that a world famous event wasn’t a disaster (no I can’t tell you the event).
The lowest point was the pandemic, when sales pretty much dropped to zero.
Competitors and operating systems have come and gone and the ecosystem for software has changed a lot, but PerfectTablePlan is still here and still paying the bills. It is about 145,000 lines of C++. Some of the code is a bit ugly and not how I would write it now. But the product is very solid, with very few bugs. The website and user documentation are also substantial pieces of work. The PDF version of the documentation is nearly 500 pages.
I now divide my time between PerfectTablePlan and my 2 other products: data wrangling software Easy Data Transform and visual planner Hyper Plan. Having multiple products keeps things varied and avoids having all my eggs in one basket. In May 2024 I released PerfectTablePlan v7 with a load of improvements and new features. And I have plenty of ideas for future improvements. I fully expect to keep working on PerfectTablePlan until I retire (I’m 59 now).
Nobody likes getting an email message telling that that the end result of all their hard work is a piece of garbage (or worse). It is a bit of a shock, when it happens the first time. One negative piece of feedback can easily offset 10 positive ones. But, hurt feelings aside, it may not be all bad.
For a start, that person actually cared enough about your product to take the time to contact you. That is not something to be taken lightly. A large number of products fail because they solve a problem that no-one cares about. Apathy is very hard to iterate on. At least you are getting some feedback. Assuming the comments aren’t completely toxic, it might be worth replying. Sometimes you can turn someone who really hates your software into a fan. Like one of those romantic comedies where an odd couple who really dislike each other end up falling in love. Indifference is much harder to work with. The people who don’t care about your product enough to communicate with you, are the dark matter of business. Non-interacting. Mysterious. Unknowable.
Negative emails may also contain a kernal of useful information, if you can look past their, sometimes less than diplomatic, phrasing. I remember having the user interface of an early version of PerfectTablePlan torn apart in a forum. Once I put my wounded pride to one side, I could see they had a point and I ended up designing a much better user interface.
In some cases the person contacting you might just be having a bad day. Their car broke down. They are going through a messy divorce. The boss shouted at them. Your product just happened to be the nearest cat they could kick. Don’t take it personally. You need a thick skin if you are to survive in business.
But sometimes there is a fundamental clash between how someone sees the world vs the model of the world embodied in your product. I once got so angry with Microsoft Project, due to this sort of clash of weltanschauung, that I came close to throwing the computer out of a window. So I understand how frustrating this can be. In this case, it is just the wrong product for them. If they have bought a licence, refund them and move on.
While polarisation is bad for society, it can good for a product. Consider a simple thought experiment. A large number of products are competing for sales in a market. Bland Co’s product is competent but unexciting. It is in everyone’s top 10, but no-one’s first choice. Exciting Co’s product is more polarizing, last choice for many, but first choice for some. Which would you rather be? Exiting Co, surely? No-one buys their second choice. Better to be selling Marmite than one of ten types of nearly identical peanut butter. So don’t be too worried about doing things that polarize opinion. For example, I think it is amusing to use a skull and crossbones icon in my seating software to show that 2 people shouldn’t be sat together. Some people have told me that they really like this. Others have told me it is ‘unprofessional’. I’m not going to change it.
Obviously we would like everyone to love our products as much as we do. But that just isn’t going to happen. You can’t please all of the people, all of the time. And, if you try, you’ll probably ending pleasing no-one. Some of the people, most of the time is probably the best you can hope for.
I’m sure we are all familiar with the idea of a technological singularity. Humans create an AI that is smart enough to create an even smarter successor. That successor then creates an even smarter successor. The process accelerates through a positive feedback loop, until we reach a technological singularity, where puny human intelligence is quickly left far behind.
Some people seem to think that Large Language Models could be the start of this process. We train the LLMs on vast corpuses of human knowledge. The LLMs then help humans create new knowledge, which is then used to train the next generation of LLMs. Singularity, here we come!
But I don’t think so. Human nature being what it is, LLMs are inevitably going to be used to churn out vast amount of low quality ‘content’ for SEO and other commercial purposes. LLM nature being what it is, a lot of this content is going to be hallucinated. In otherwords, bullshit. Given that LLMs can generate content vastly faster than humans can, we could quickly end up with an Internet that is mostly bullshit. Which will then be used to train the next generation of LLM. We will eventually reach a bullshit singularlity, where it is almost impossible to work out whether anything on the Internet is true. Enshittification at scale. Well done us.
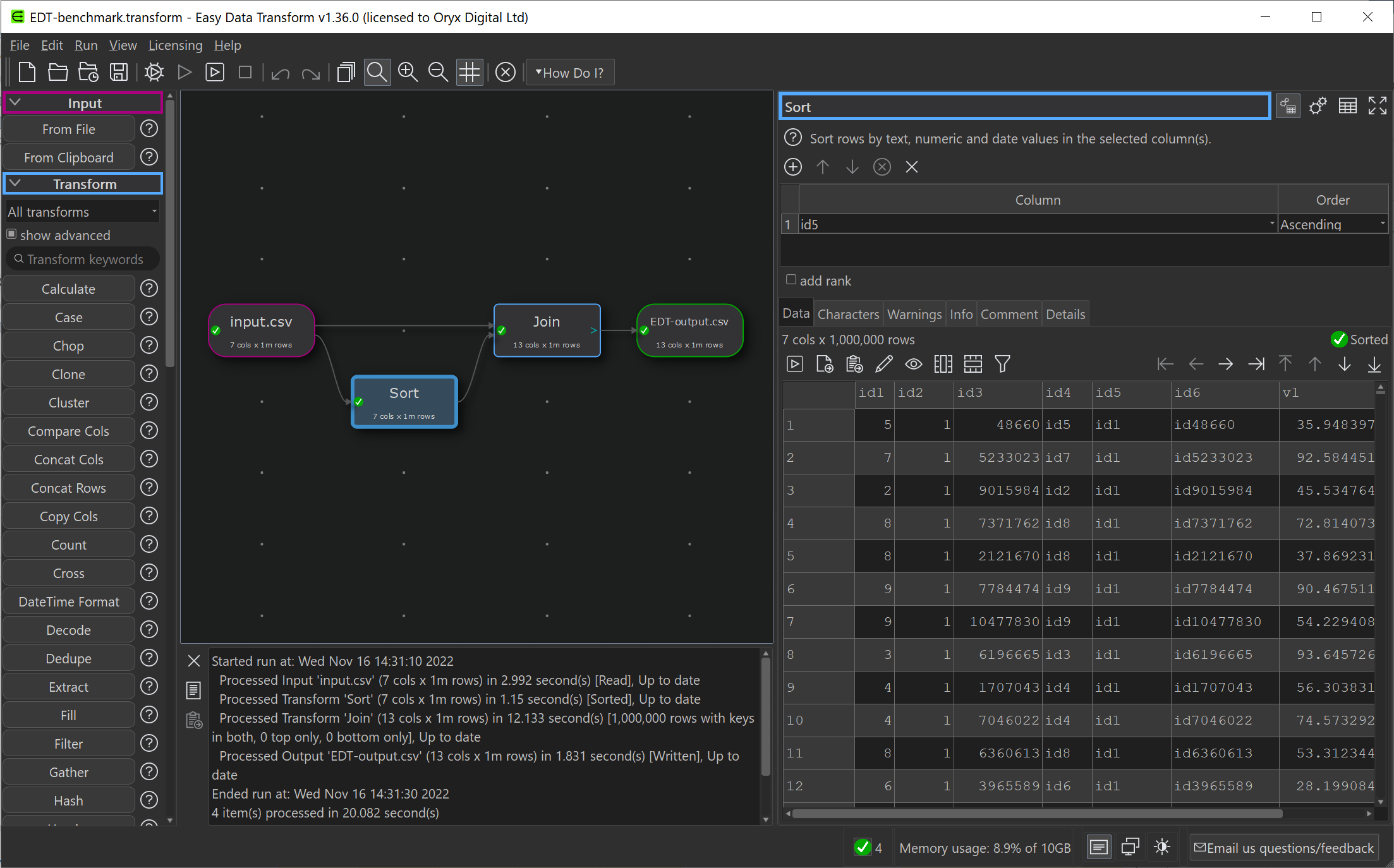
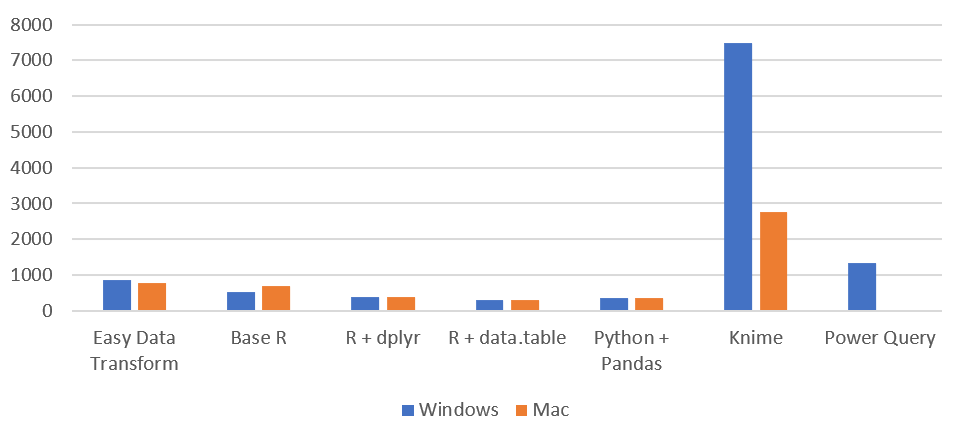
I have been gradually improving my data wrangling tool, Easy Data Transform, putting out 70 public releases since 2019. While the product’s emphasis is on ease of use, rather than pure performance, I have been trying to make it fast as well, so it can cope with the multi-million row datasets customers like to throw at it. To see how I was doing, I did a simple benchmark of the most recent version of Easy Data Transform (v1.37.0) against several other desktop data wrangling tools. The benchmark did a read, sort, join and write of a 1 million row CSV file. I did the benchmarking on my Windows development PC and my Mac M1 laptop.
Here is an overview of the results:
Time by task (seconds), on Windows without Power Query (smaller is better):
I have left Excel Power Query off this graph, as it is so slow you can hardly see the other bars when it is included!
Time by task (seconds) on Mac (smaller is better):
Memory usage (MB), Windows vs Mac (smaller is better):
So Easy Data Transform is nearly as fast as it’s nearest competitor, Knime, on Windows and a fair bit faster on an M1 Mac. It is also uses a lot less memory than Knime. However we have got some way to go to catch up with the Pandas library for Python and the data.table package for R, when it comes to raw performance. Hopefully I can get nearer to their performance in time. I was forbidden from including benchmarks for Tableau Prep and Alteryx by their licensing terms, which seems unnecessarily restrictive.
Looking at just the Easy Data Transform results, it is interesting to notice that a newish Macbook Air M1 laptop is significantly faster than a desktop AMD Ryzen 7 desktop PC from a few years ago.
Apple has transitioned Macs from Intel to ARM (M1/M2) chips. In the process it has provided an emulation layer (Rosetta2) to ensure that the new ARM Macs can still run applications created for Intel Macs. The emulation works very well, but is quoted to be some 20% slower than running native ARM binaries. That may not seem like a lot, but it is significant on processor intensive applications such as my own data wrangling software, which often processes datasets with millions of rows through complex sequences of merging, splitting, reformatting, filtering and reshaping. Also people who have just spent a small fortune on a shiny new ARM Mac can get grumpy about not having a native ARM binary to run on it. So I have been investigating moving Easy Data Transform from an Intel binary to a Universal (‘fat'[1]) binary containing both Intel and ARM binaries. This is a process familiar from moving my seating planner software for Mac from PowerPC to Intel chips some years ago. Hopefully I will have retired before the next chip change on the Mac.
My software is built on-top of the excellent Qt cross-platfom framework. Qt announced support for Mac Universal binaries in Qt 6.2 and Qt 5.15.9. I am sticking with Qt 5 for now, because it better supports multiple text encodings and because I don’t see any particular advantage to switching to Qt 6 yet. But, there is a wrinkle. Qt 5.15.3 and later are only available to Qt customers with commercial licenses. I want to use the QtCharts component in Easy Data Transform v2, and QtCharts requires a commercial license (or GPL, which is a no-go for me). I also want access to all the latest bug fixes for Qt 5. So I decided to switch from the free LGPL license and buy a commercial Qt license. Thankfully I was eligible for the Qt small business license which is currently $499 per year. The push towards commercial licensing is controversial with Qt developers, but I really appreciate Qt and all the work that goes into it, so I am happy to support the business (not enough to pay the eye-watering fee for a full enterprise license though!).
Moving from producing an Intel binary using LGPL Qt to producing a Universal binary using commercial Qt involved several major stumbling points that took me hours and a lot of googling to sort out. I’m going to spell them out here to save you that pain. You’re welcome.
The latest Qt 5 LTS releases are not available via the Qt maintenance tool if you have open source Qt installed. After you buy your commercial licence you need to delete your open source installation and all the associated license files. Here is the information I got from Qt support:
I assume that you were previously using open source version, is that correct?
Qt 5.15.10 should be available through the maintenance tool but it is required to remove the old open source installation completely and also remove the open source license files from your system.
So, first step is to remove the old Qt installation completely. Then remove the old open source licenses which might exist. Instructions for removing the license files:
****************************
Unified installer/maintenancetool/qtcreator will save all licenses (downloaded from the used Qt Account) inside the new qtlicenses.ini file. You need to remove the following files to fully reset the license information.
Windows
"C:/Users/%USERNAME%/AppData/Roaming/Qt/qtlicenses.ini"
"C:/Users/%USERNAME%/AppData/Roaming/Qt/qtaccount.ini"
Linux
"/home/$USERNAME/.local/share/Qt/qtlicenses.ini"
"/home/$USERNAME/.local/share/Qt/qtaccount.ini"
OS X
"/Users/$USERNAME/Library/Application Support/Qt/qtlicenses.ini"
"/Users/$USERNAME/Library/Application Support/Qt/qtaccount.ini"
As a side note: If the files above cannot be found $HOME/.qt-license(Linux/macOS) or %USERPROFILE%\.qt-license(Windows) file is used as a fallback. .qt-license file can be downloaded from Qt Account. https://account.qt.io/licenses
Be sure to name the Qt license file as ".qt-license" and not for example ".qt-license.txt".
***********************************************************************
After removing the old installation and the license files, please download the new online installer via your commercial Qt Account.
You can login there at:
https://login.qt.io/login
After installing Qt with commercial license, it should be able to find the Qt 5.15.10 also through the maintenance tool in addition to online installer.
Then you need to download the commercial installer from your online Qt account and reinstall all the Qt versions you need. Gigabytes of it. Time to drink some coffee. A lot of coffee.
In your .pro file you need to add:
macx {
QMAKE_APPLE_DEVICE_ARCHS = x86_64 arm64
}
Note that the above doubles the build time of your application, so you probably don’t want it set for day to day development.
You can use macdeployqt to create your deployable Universal .app but, and this is the critical step that took me hours to work out, you need to use <QtDir>/macos/bin/macdeployqt not <QtDir>/clang_64/bin/macdeployqt . Doh!
You can check the .app is Universal using the lipo command, e.g.:
I was able to use my existing practise of copying extra files (third party libraries, help etc) into the .app file and then digitally signing everything using codesign –deep [2]. Thankfully the only third party library I use apart from Qt (the excellent libXL library for Excel) is available as a Universal framework.
I did all the above on an Intel iMac using the latest Qt 5 LTS release (Qt 5.15.10) and XCode 13.4 on macOS 12. I then tested it on an ARM MacBook Air. No doubt you can also build Universal binaries on an ARM Mac.
Unsurprisingly the Universal app is substantially larger than the Intel-only version. My Easy Data Transform .dmg file (which also includes a lot of help documentation) went from ~56 MB to ~69 MB. However that is still positively anorexic compared to many bloated modern apps (looking at you Electron).
A couple of tests I did on an ARM MacBook Air showed ~16% improvement in performance. For example joining two 500,000 row x 10 column tables went from 4.5 seconds to 3.8 seconds. Obviously the performance improvement depends on the task and the system. One customer reported batch processing 3,541 JSON Files and writing the results to CSV went from 12.8 to 8.1 seconds, a 37% improvement.
[1] I’m not judging.
[2] Apparently the use of –deep is frowned on by Apple. But it works (for now anyway). Bite me, Apple.
Tabular data is everywhere. I support reading and writing tabular data in various formats in all 3 of my software application. It is an important part of my data transformation software. But all the tabular data formats suck. There doesn’t seem to be anything that is reasonably space efficient, simple and quick to parse and text based (not binary) so you can view and edit it with a standard editor.
Most tabular data currently gets exchanged as: CSV, Tab separated, XML, JSON or Excel. And they are all highly sub-optimal for the job.
CSV is a mess. One quote in the wrong place and the file is invalid. It is difficult to parse efficiently using multiple cores, due to the quoting (you can’t start parsing from part way through a file). Different quoting schemes are in use. You don’t know what encoding it is in. Use of separators and line endings are inconsistent (sometimes comma, sometimes semicolon). Writing a parser to handle all the different dialects is not at all trivial. Microsoft Excel and Apple Numbers don’t even agree on how to interpret some edge cases for CSV.
Tab separated is a bit better than CSV. But can’t store tabs and still has issues with line endings, encodings etc.
XML and JSON are tree structures and not suitable for efficiently storing tabular data (plus other issues).
There is Parquet. It is very efficient with it’s columnar storage and compression. But it is binary, so can’t be viewed or edited with standard tools, which is a pain.
Don’t even get me started on Excel’s proprietary, ghastly binary format.
Why can’t we have a format where:
Encoding is always UTF-8
Values stored in row major order (row 1, row2 etc)
Columns are separated by \u001F (ASCII unit separator)
Rows are separated by \u001E (ASCII record separator)
Er, that’s the entire specification.
No escaping. If you want to put \u001F or \u001E in your data – tough you can’t. Use a different format.
It would be reasonably compact, efficient to parse and easy to manually edit (Notepad++ shows the unit separator as a ‘US’ symbol). You could write a fast parser for it in minutes. Typing \u001F or \u001E in some editors might be a faff, but it is hardly a showstopper.
It could be called something like “unicode separated value” (hat tip to @fakeunicode on Twitter for the name) or “unit separated value” with file extension .usv. Maybe a different extension could used when values are stored in column major order (column1, column 2 etc).
Is there nothing like this already? Maybe there is and I just haven’t heard of it. If not, shouldn’t there be?
It has been pointed at the above will give you a single line of text in an editor, which is not great for human readability. A quick fix for this would be to make the record delimiter a \u001E character followed by an LF character. Any LF that comes immediately after an \u001E would be ignored when parsing. Any LF not immediately after an \u001E is part of the data. I don’t know about other editors, but it is easy to view and edit in Notepad++.