Twice this week, I have come across embarrassingly bad data.
The first instance is the UK government’s fuel finder data. This is a downloadable CSV file of fuel station locations and prices from around the UK. A potentially very useful database, especially during the current conflict in the Middle East. A customer suggested it as a possible practice dataset for my data wrangling and visualization software, Easy Data Transform . So I had a quick look and spotted some glaring errors within a few minutes.
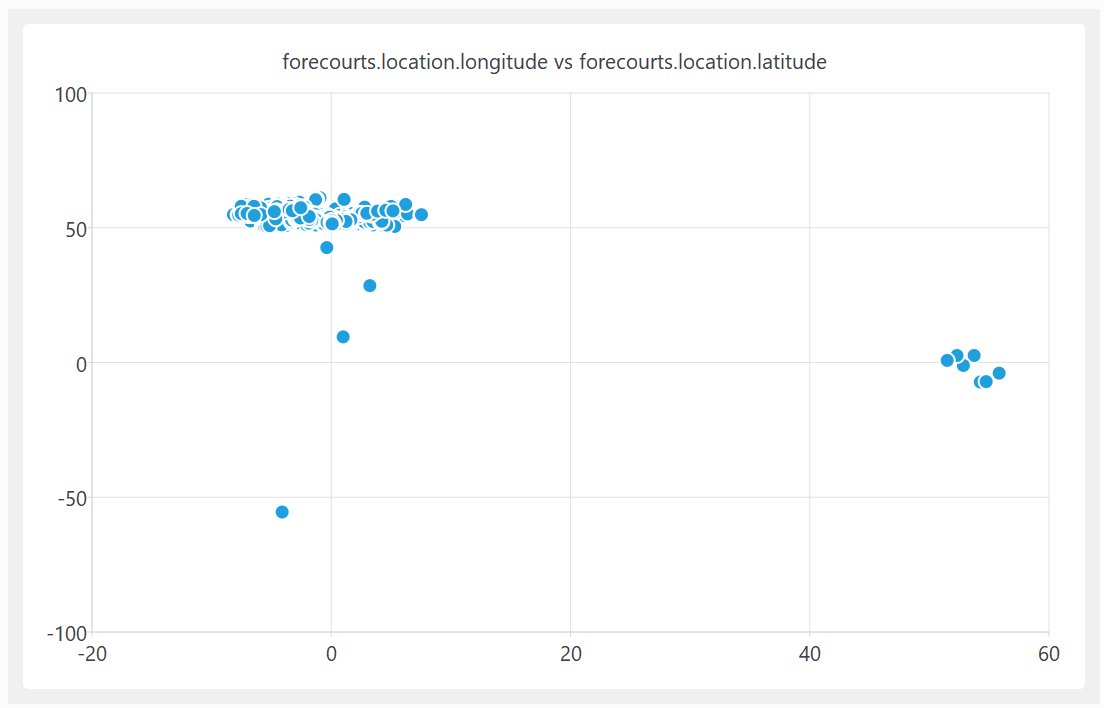
A quick plot of the latitude and longitude shows some clear outliers:
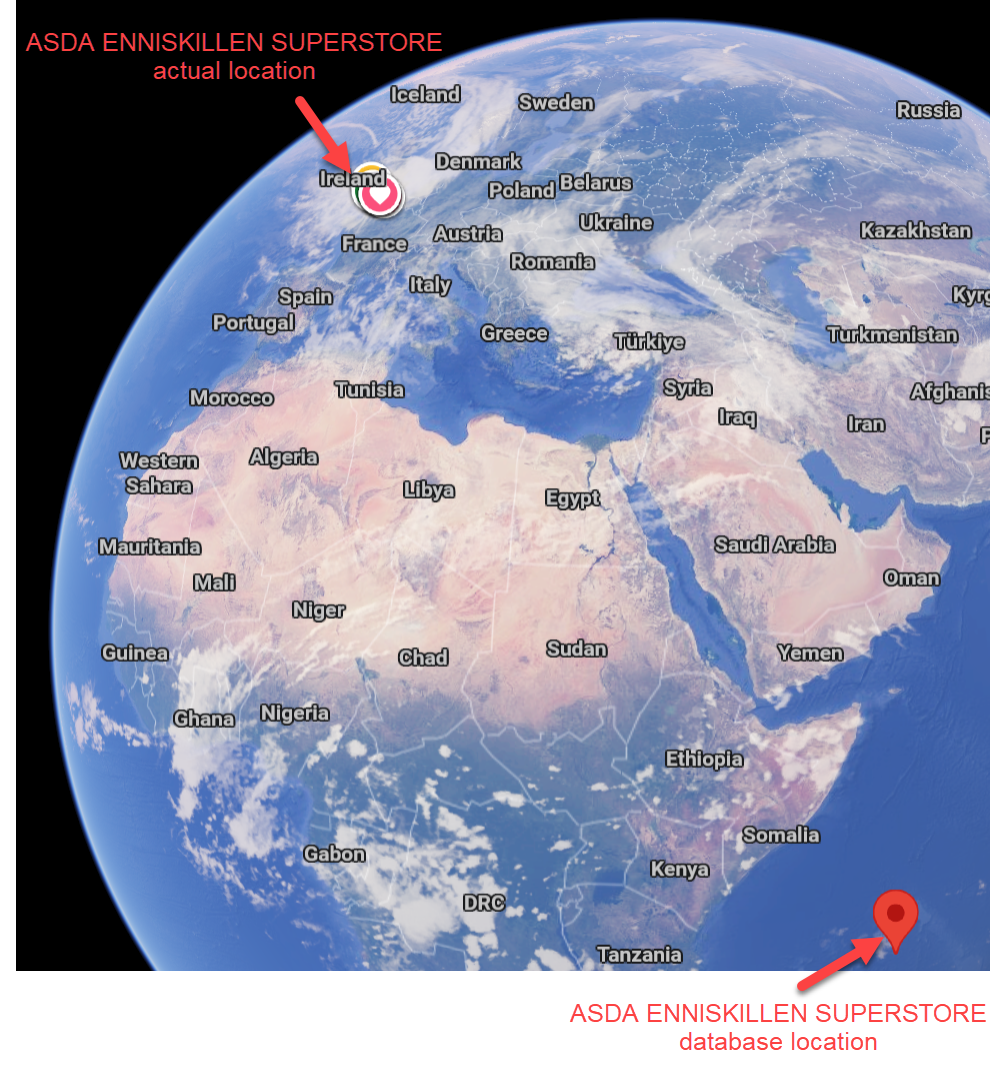
On further investigation, some of these UK fuel stations are apparently located in the Indian and South Atlantic oceans. In at least one case, it looks like they got the latitude and longitude the wrong way around.
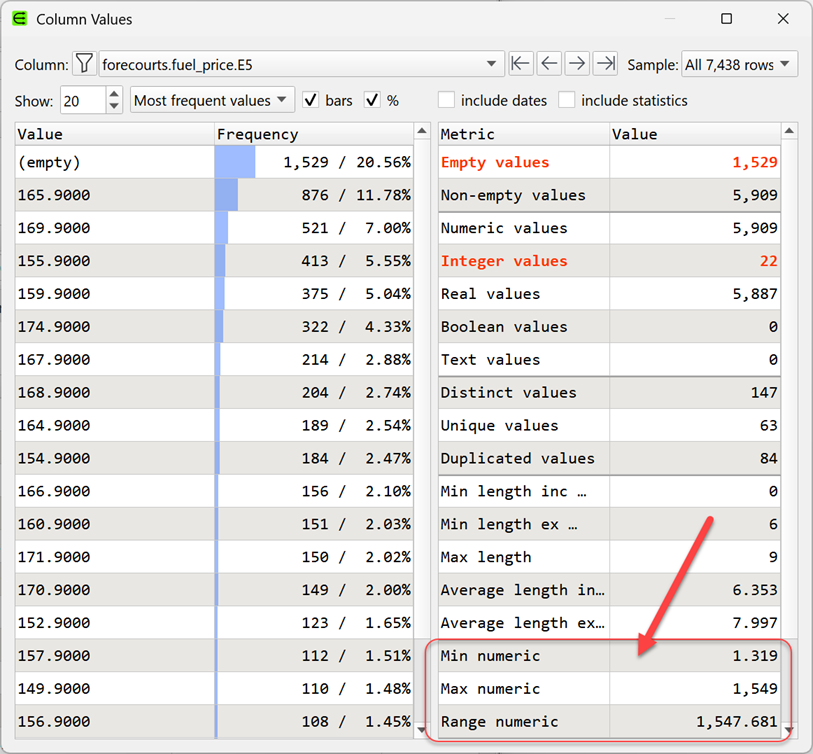
A quick look at the fuel price columns also shows some major issues:
The ratio between the most expensive and cheapest fuel (per litre) is 1538:1. Clearly wrong.
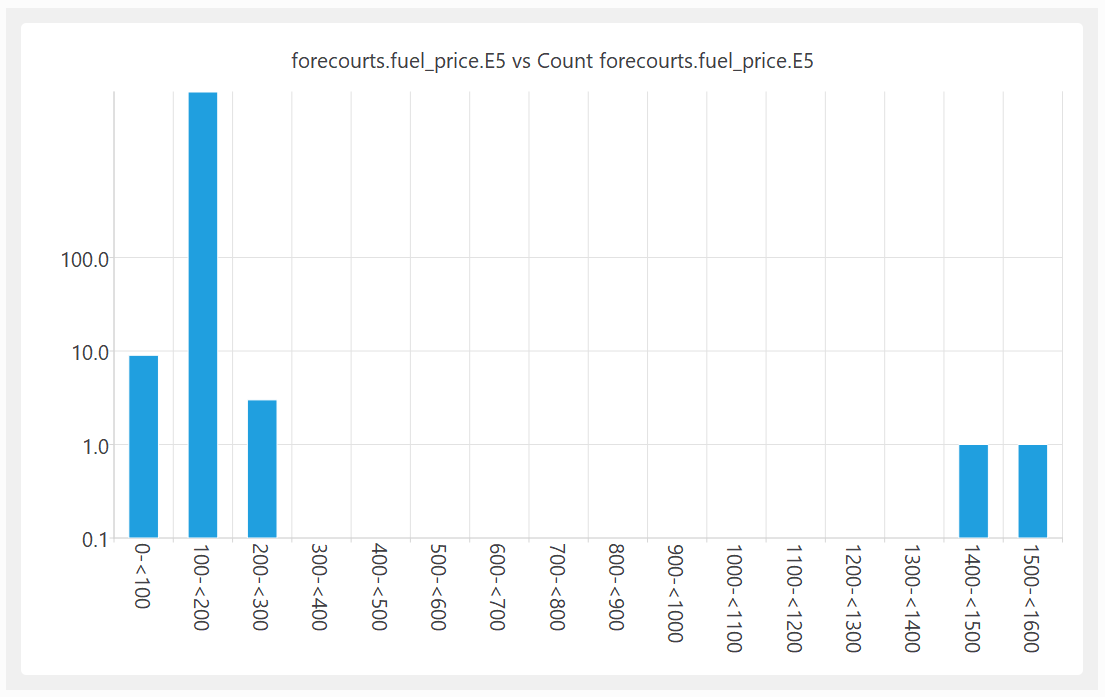
Shown as a histogram with a logarithmic Y axis:
I am guessing that the reason for this bad data is that the fuel stations are submitting their own data and, humans being humans, they make mistakes. But then the government is publishing the data without even the most basic checks. That just isn’t good enough.
I reported the problem on 22-Mar-2026. They acknowledge my email on 24-Mar-2026 (“Thank you for sharing this, we have passed this on to the technical team to have a look at.”). The CSV file published on 29-Mar-2026 still has the garbage data.
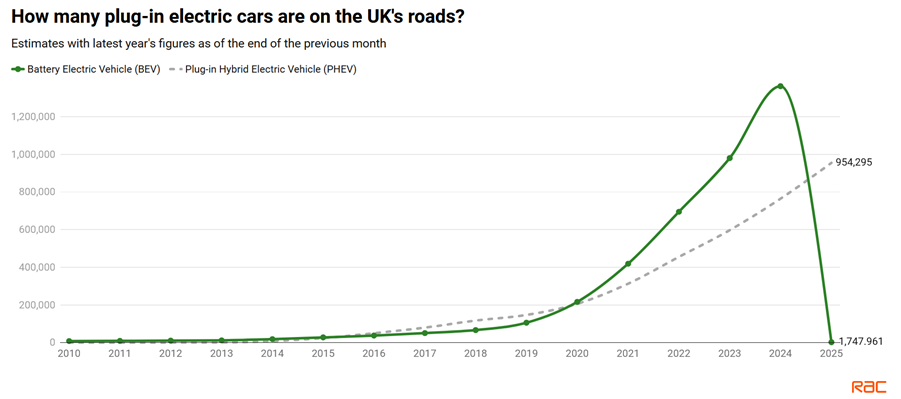
The second instance is a report on electric cars from UK motoring organization, the RAC. The first graph in the article is this:
Did the number of Battery Electric Vehicles on the UK’s roads suddeny drop from ~1.4 million in 2024 to ~0.0017 million in 2025? What happened to those ~1.4 million vehicles? I’m guessing that someone got their thousands and millions mixed up. But then they published the report with this glaring error. Did anyone mathematically literate even check this graph?
Lousy data undermines trust in institutions and can lead to bad decisions. I fear we are heading for a future where LLMs generate data, which people don’t bother to properly check. This data is then used train LLMs. The error is then much harder to spot once it is served back without the original source by LLMs. A slop-apocalypse.
Authors should have their work proof read, programmers should test their code and data people should do basic data validation. Let’s take some pride in our work.
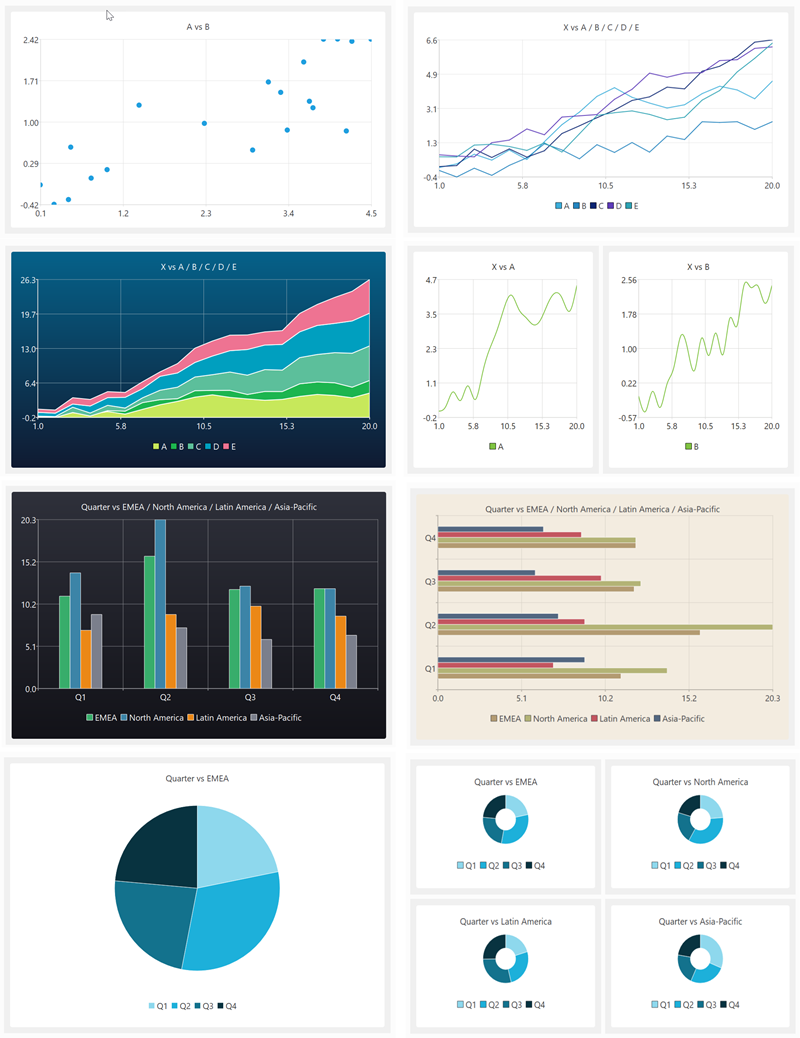
My data wrangling product, Easy Data Transform, got a major upgrade yesterday, with the addition of data visualization capabilities. Here are some examples of what it can produce in a few clicks:
You can see this new visualization feature in action in the video below:
(Likes and subscribes help me with the YouTube algorithm and are much appreciated)
Human brains are highly developed for visual processing. But data is often messy and in the wrong form for visualization. So data wrangling and visualization, tightly integrated together, is a powerful combination. It was a lot of work, but it makes Easy Data Transform a much more complete, end-to-end, solution. No more pasting data into Excel to get a chart!
At the same time, I have segmented Easy Data Transform into 2 products: Easy Data Transform Core Edition (data wrangling, one-time fee $99) and Easy Data Transform Advanced Edition (data wrangling+visualization, one-time fee $198). The Advanced Edition is a paid upgrade from the original product. Optional, of course. I sweetened the deal with a time-limited discount for existing customers who want to upgrade to Advanced Edition. The response from Easy Data Transform customers has been very positive.
Have you got some messy data, you want to turn into insights? Why not give Easy Data Transform Advanced Edition a try? It:
Runs natively on Windows and Mac.
Is drag and drop (no syntax to remember).
Does not store your precious data on someone else’s server.
Is deterministic and will not hallucinate!
Can process millions of rows in seconds.
Can create re-usable templates for repeatable processes.
You can download a free trial here. And you can get 15% off Easy Data Transform Advanced Edition until 17-Jul-2026 using this discount link.
I am always on the lookout for cost and time effective ways that I can market my software products. Previously, I have had quite a lot of success with Google Adwords Pay Per Click ads. However, the law of shitty clickthroughs means that advertising platforms generally get less and less profitable (for the advertisers) over time. And Google Adwords is a case study of that law in action. As Reddit is a less mature advertising platform, I thought it might still offer opportunities for a decent return. So I decided to experiment with advertising my data munging software, Easy Data Transform, on Reddit.
[By the way, I understand that nobody goes to Reddit because they want to see ads. But commercial products need to market themselves to survive, and Reddit probably wouldn’t exist without ads. Yay capitalism.]
Setup
The basic process to get started with Reddit Ads is:
Sign up for a Reddit Ads account.
Enter your details and credit card number.
Create a campaign.
Create one or more ad groups for your campaign. Choose a bid for each ad group, which countries you want it shown in and who you want it shown to.
Create one or more ads for each group.
Add the Reddit tracking pixel to every page of your website.
Set up conversion goals.
All pretty standard stuff for anyone who has used Google Adwords. The twist with Reddit is that you can advertise to communities (sub-Reddits), rather than based on search keywords. For example, Easy Data Transform is a much better tool for most data wrangling tasks than Excel, so I can bid to show ads targeted at Excel users in communities such as: reddit.com/r/excel/ and reddit.com/r/ExcelTips/.
Like Adwords, there are various ways to bid. I don’t want the advertising platform to set the bid prices for me (because I’m not insane), so I opted for fixed price bids of between $0.20 and $0.40 per click. Some of the ad groups suggested much higher bids than that. For example, the suggested bid for my Excel ad group is $0.79 to $4.79 per click!
However, Easy Data Transform is only a one time payment of $99. Paying more than $0.40 per click is unlikely to be profitable for me, especially when you factor in support costs. So that is the maximum I was prepared to bid. Also, the suggested bids are just the ad platform trying to push up the bid price. Something that anyone who has used Google Adwords will be all too familiar with. I was still able to get clicks, bidding significantly less than the recommended minimum.
I also set a daily maximum for each ad group, just in case I had messed up and added a zero in a bid somewhere.
I created multiple ads for each ad group, with a range of different text and images specific to the communities targeted. Here are some of the ones I ran in the Excel ad group:
I didn’t try to use edgy images or memes, because that isn’t really my style. There is an option to turn comments on below ads. As Reddit users are generally not well-disposed to ads, I didn’t try turning this on.
Based on hard-won experience with Google Adwords, I only set my ads to run in wealthy countries. I also restricted my ads to people on desktop devices as Easy Data Transform only runs on the desktop.
When Easy Data Transform is installed, it opens a page on my website with some instructions. So I used this to set up the Reddit conversion tracking to count the number of times a click ended up with a successful install of either the Windows or Mac version of Easy Data Transform.
I monitored the performance of the ads and disabled those that has poor click through or conversion rates and made variants of the more successful ones. Darwinian evolution for ads. I ended up creating 70 ads across 15 ad groups, targeting 50 communities.
I wasted an hour trying to get Reddit to recognize that I had installed their tracking pixel. But, overall, I found the Reddit Ads relatively simple to setup and monitor. Especially compared to the byzantine monstrosity that Google Adwords has become.
Reddit advertises a deal where you can get $500 of free ads.
But the link was broken when I clicked on it. Someone else I spoke to said they had tried to find out more, but gave up when they found out you had to have a phone call with a sales person at Reddit.
Results
I ran my experiment from 08-Jul-2025 to 31-Jul-2025. These are the stats, according to reddit.
Spend
$851.04
Impressions
490,478
Clicks
3,585
Windows installs
177
Mac installs
63
Total installs
240
Click Through Rate
0.73%
Cost Per Click
$0.24
Click to install conversion rate
6.59%
Cost Per Install
$3.55
I generally reckon that somewhere around 10% of people who install are going on to buy. So $3.55 per install would mean around $35.50 cost per sale, which is reasonable for a $99 sale. So that all looks quite encouraging.
But, comparing the Reddit number to the numbers I get from Google Analytics and my web logs, I think the Reddit numbers are dubious. At best. In a week when Reddit says it sent me 1174 clicks, Google Analytics says I received 590 referrals from Reddit and my web log says I received 639 referrals from Reddit. Some of the difference may be due to comparing sessions with clicks, time zones etc. But it looks fishy.
The discrepancy is even greater if you look at conversions. The total installs per week reported by Google Analytics and my web logs didn’t go up anything like you would expect from looking at the Reddit conversion numbers. If you dig a bit further, you find that Reddit uses ‘modeled conversions‘ to:
“Gain a more complete view of your ads performance with modeled conversions, which leverages machine learning to bridge attribution gaps caused by signal loss.”
Uh huh. Sounds suspiciously like ‘making shit up’.
And then there are the sales. Or lack of. I don’t have detailed tracking of exactly where every sale comes from. But I estimate that my $851 outlay on ads resulted in between $0 and $400 in additional sales. Which is not good, given that I don’t have VC money to burn. Especially when you factor in the time taken to run this experiment.
The top 5 countries for spend were:
Italy
Spain
France
Germany
Singapore
The US only accounted for 0.28% of impressions, 13 clicks and $3.81 in spend. Presumably because the US market is more competitive, and I wasn’t bidding enough to get my ads shown.
You can look at various breakdowns by country, community, device etc. This is helpful. But some of the breakdowns make no sense. For example, it says that 41% of the click throughs from people reading Mac-related communities were from Windows PCs. That sounds very unlikely!
But the worst is still to come. Feast your eyes on this Google Analytics data from my website:
Average engaged time per active user (seconds)
Engaged sessions per active user
Google / organic
33
0.75
Successfulsoftware.net / referral
31
0.74
Youtube.com / referral
27
0.86
Chatgpt.com / referral
24
0.69
Google / CPC
16
0.65
Reddit / referral
8
0.25
8 seconds! That is the mean, not the median. Yikes. And 75% of the sessions didn’t result in any meaningful engagement. This makes me wonder if the majority of the Reddit clicks are accidental.
I had intended to spend $1000 on this experiment, but the results were sufficiently horrible that I stopped before then.
If I had spent a lot of time tweaking the ad images and text, landing pages, communities and countries, then I could probably have improved things a bit. But I doubt I could ever get a worthwhile return on my time and money.
If the lifetime value of a sale is a lot more than $99 for you, or your product is a good fit for Reddit, then Reddit Ads might be worth trying. But be sure not to take any Reddit numbers at face value.
I released version 1 of my table seating planning software, PerfectTablePlan, in February 2005. 20 years ago this month. It was a different world. A world of Windows, shareware and CDs. A lot has changed since then, but PerfectTablePlan is now at version 7 and still going strong.
PerfectTablePlan v1
PerfectTablePlan v7
I have released several other products since then, and done some training and consulting, but PerfectTablePlan remains my most successful product. It’s success is due to a lot of hard work, and a certain amount of dumb luck.
I was getting married and I volunteered to do the seating plan for our wedding reception. It sounded like a relatively straightforward optimization problem, as we only had 60 guests and no family feuds to worry about. But it was surprisingly difficult to get right. I looked around for some software to help me. There were a couple of software packages, but I wasn’t impressed. I could do better myself! So I wrote a (very rough) first version, which I used for our wedding.
Things weren’t going great at my day job, at a small software startup. Maybe I could commercialize my table planner? I was a bit wary, as my potential competitors all seemed rather moribund and I didn’t think I would be able to make a living off it. But I thought I could do everything worth doing in 6-12 months and then start on the next product. Wrong on both counts!
Web-based software was still in its infancy in 2005. So I decided to write it as desktop software using C++ and cross-platform framework Qt, which I had plenty of experience in. Initially, I just released a Windows version. But I later added a Mac version as well. Qt has had its commercial ups and downs in the last 20 years, but it has grown with me and is now very robust, comprehensive and well documented. I think I made a good choice.
I financed PerfectTablePlan out of my own savings and it has been profitable every year since version 1 was launched. I could have taken on employees and grown the business, but I preferred to keep it as a lifestyle business. My wife does the accounts and proof reading and I do nearly everything else, with a bit of help from my accountant, web designers and a few other contractors. I don’t regret that decision. 20 years without meetings, ties or alarm clocks. My son was born 18 months after PerfectTablePlan was launched and it has been great to have the flexibility to be fully present as a Dad.
CDs, remember them? I sent out around 5,000 CDs (with some help from my father), before I stopped shipping CDs in 2016.
During the lifetime of PerfectTablePlan it became clear that things were increasingly moving to the web. But I couldn’t face rewriting PerfectTablePlan from scratch for the web. Javascript. Ugh. Also PerfectTablePlan is quite compute intensive, using a genetic algorithm to generate an automated seating plan and I felt it was better running this on the customer’s local computers than my server. And some of my customers consider their seating plans to be confidential and don’t want to store them on third party servers. So I decided to stick with desktop. But, if I was starting PerfectTablePlan from scratch now, I might make a different decision.
Plenty of strange and wonderful things have happened over the last 20 years, including:
PerfectTablePlan has been used by some very famous organizations for some very famous events (which we mostly don’t have permission to mention). It has seated royalty, celebrities and heads of state.
A mock-up of PerfectTablePlan, including icons I did myself, was used without our permission by Sony in their ‘Big day’ TV comedy series. I threated them with legal action. Years later, I am still awaiting a reply.
I got to grapple with some interesting problems, including the mathematics of large combinatorial problems and elliptical tables. Some customers have seated 4,000 guests and 4000! (4000x3999x3998 .. x 1) is a mind-bogglingly huge number.
A well known wedding magazine ran a promotion with a valid licence key clearly visible in a photograph of a PerfectTablePlan CD. I worked through the night to release a new version of PerfectTablePlan that didn’t work with this key.
I once had to stay up late, in a state of some inebriation, to fix an issue so that a world famous event wasn’t a disaster (no I can’t tell you the event).
The lowest point was the pandemic, when sales pretty much dropped to zero.
Competitors and operating systems have come and gone and the ecosystem for software has changed a lot, but PerfectTablePlan is still here and still paying the bills. It is about 145,000 lines of C++. Some of the code is a bit ugly and not how I would write it now. But the product is very solid, with very few bugs. The website and user documentation are also substantial pieces of work. The PDF version of the documentation is nearly 500 pages.
I now divide my time between PerfectTablePlan and my 2 other products: data wrangling software Easy Data Transform and visual planner Hyper Plan. Having multiple products keeps things varied and avoids having all my eggs in one basket. In May 2024 I released PerfectTablePlan v7 with a load of improvements and new features. And I have plenty of ideas for future improvements. I fully expect to keep working on PerfectTablePlan until I retire (I’m 59 now).
I released Easy Data Transform v2 today. After no fewer than 80 (!) v1 production releases since 2019, this is the first paid upgrade.
Major improvements include:
Schema versioning, so you can automatically handle changes to the column structure of an input (e.g. additional or missing columns).
A new Verify transform so you can check a dataset has the expected values.
Currently there are 48 different verification checks you can make:
At least 1 non-empty value
Contains
Don’t allow listed values
Ends with
Integer except listed special value(s)
Is local file
Is local folder
Is lower case
Is sentence case
Is title case
Is upper case
Is valid EAN13
Is valid email
Is valid telephone number
Is valid UPC-A
Match column name
Matches regular expression
Maximum characters
Maximum number of columns
Maximum number of rows
Maximum value
Minimum characters
Minimum number of columns
Minimum number of rows
Minimum value
No blank values
No carriage returns
No currency
No digits
No double spaces
No duplicate column names
No duplicate values
No empty rows
No empty values
No gaps in values
No leading or trailing whitespace
No line feeds
No non-ASCII
No non-printable
No punctuation
No symbols
No Tab characters
No whitespace
Numeric except listed special value(s)
Only allow listed values
Require listed values
Starts with
Valid date in format
You can see any fails visually, with colour coding by severity:
Side-by-side comparison of dataset headers:
Side-by-side comparison of dataset data values:
Lots of extra matching options for the Lookup transform:
Allowing you to do exotic lookups such as:
Plus lots of other changes.
In v1 there were issues related to how column-related changes cascaded through the system. This was the hardest thing to get right, and it took a fairly big redesign to fix all the issues. As a bonus, you can now disconnect and reconnect nodes, and it remembers all the column-based options (within certain limits). These changes make Easy Data Transform feel much more robust to use, as you can now make lots of changes without worrying too much about breaking things further downstream.
Easy Data Transform now supports:
9 input formats (including various CSV variants, Excel, XML and JSON)
66 different data transforms (such as Join, Filter, Pivot, Sample and Lookup)
11 output formats (including various CSV variants, Excel, XML and JSON)
56 text encodings
This allows you to snap together a sequence of nodes like Lego, to very quickly transform or analyse your data. Unlike a code-based approach (such as R or Python) or a command line tool, it is extremely visual, with pretty-much instant feedback every time you make a change. Plus, no pesky syntax to remember.
Eating my own dogfood, using Easy Data Transform to create an email marketing campaign from various disparate data sources (mailing lists, licence key databases etc).
Easy Data Transform is all written in C++ with memory compression and reference counting, so it is fast and memory efficient and can handle multi-million row datasets with no problem.
While many of my competitors are transitioning to the web, Easy Data Transform remains a local tool for Windows and Mac. This has several major advantages:
Your sensitive data stays on your computer.
Less latency.
I don’t have to pay your compute and bandwidth costs, which means I can charge an affordable one-time fee for a perpetual licence.
I think privacy is only going to become ever more of a concern as rampaging AIs try to scrape every single piece of data they can find.
Usage-based fees for online data tools are no small matter. For a range of usage fee horror stories, such as enabling debug logging in a large production ETL pipeline resulting in $100k of extra costs in a week, see this Reddit post. Some of my customers have processed more than a billion rows in Easy Data Transform. Not bad for $99!
It has been a lot of hard work, but I am please with how far Easy Data Transform has come. I think Easy Data Transform is now a comprehensive, fast and robust tool for file-based data wrangling. If you have some data to wrangle, give it a try! It is only $99+tax ($40+tax if you are upgrading from v1) and there is a fully functional, 7 day free trial here:
I am very grateful to my customers, who have been a big help in providing feedback. This has improved the product no end. Many heads are better than one!
The next big step is going to be adding the ability to talk directly to databases, REST APIs and other data sources. I also hope at some point to add the ability to visualize data using graphs and charts. Watch this space!
Visual programming tools (also called ‘no-code’ or ‘low-code’) have been getting a lot of press recently. This, in turn, has generated a lot of discussion about whether visual or text based programming (coding) is ‘best’. As someone who uses text programming (C++) to create a visual programming data wrangling tool (Easy Data Transform) I have some skin in this game and have thought about it quite a bit.
At some level, everything is visual. Text is still visual (glyphs). By visual programming here I specifically mean software that allows you to program using nodes (boxes) and vertexes (arrows), laid out on a virtual canvas using drag and drop.
A famous example of this sort of drag and drop visual programming is Yahoo Pipes:
But there are many others, including my own Easy Data Transform:
Note that I’m not talking about Excel, Scratch or drag and drop GUI designers. Although some of the discussion might apply to them.
By text programming, I mean mainstream programming languages such as Python, Javascript or C++, and associated tools. Here is the QtCreator Interactive Development Environment (IDE) that I use to write C++ in, to create Easy Data Transform:
The advantages of visual programming are:
Intuitive. Humans are very visual creatures. A lot of our brain is given over to visual processing and our visual processing bandwidth is high. Look at pretty much any whiteboard, at any company, and there is a good chance you will see boxes and arrows. Even in non-techie companies.
Quicker to get started. Drag and drop tools can allow you to start solving problems in minutes.
Higher level abstractions. Which means you can work faster (assuming they are the right abstractions).
Less hidden state. The connections between nodes are shown on screen, rather than you having to build an internal model in your own memory.
Less configuration. The system components work together without modification.
No syntax to remember. Which means it is less arcane for people who aren’t experienced programmers.
Less run-time errors, because the system generally won’t let you do anything invalid. You don’t have to worry about getting function names or parameter ordering and types right.
Immediate feedback on every action. No need to compile and run.
The advantages of text programming are:
Denser representation of information.
Greater flexibility. Easier to do things like looping and recursion.
Better tooling. There is a vast ecosystem of tools for manipulating text, such as editors and version control systems.
Less lock-in. You can generally move your C++ or Python code from one IDE to another without much problem.
More opportunities for optimization. Because you have lower-level access there is more scope to optimize speed and/or memory as required.
The advantages and disadvantages of each are two sides of the same coin. A higher level of abstraction makes things simpler, but also reduces the expressiveness and flexibility. The explicit showing of connections can make things clearer, but can also increase on-screen clutter.
The typical complaints you hear online about visual programming systems are:
It makes 95% of things easy and 5% of things impossible
Visual programming systems are not as flexible. However many visual programming systems will let you drop down into text programming, when required, to implement that additional 5%.
Jokes aside, I think this hybrid approach does a lot to combine the strengths of both approaches.
It doesn’t scale to complex systems
Managing complex systems has been much improved over the years in text programming, using techniques such as hierarchy and encapsulation. But there is no reason these same techniques can’t also be applied to visual programming.
It isn’t high enough performance
The creators of a visual programming system are making a lot of design decisions for you. If you need to tune a system for high performance on a particular problem, then you probably need the low level control that text based programming allows. But with most problems you probably don’t care if it takes a few extra seconds to run, if you can do the programming in a fraction of the time. Also, a lot of visual programming systems are pretty fast. Easy Data Transform can join 2 one million row datasets on a laptop in ~5 seconds, which is faster than base R.
I’m sure we’ve all seen examples of spaghetti diagrams. But you can also create horrible spaghetti code with text programming. Also, being able to immediately see that a visual program has been sloppily constructed might serve as a useful cue.
If you are careful to layout your nodes, you can keep things manageable (ravioli, rather than spaghetti). But it starts to become tricky when you have 50+ nodes with a moderate to high degree of connectivity, especially if there is no support for hierarchy (nodes within nodes).
Automatic layout of graphs for easier comprehension (e.g. to minimize line crossings) is hard (NP-complete, in the same class of problems as the ‘travelling salesman’).
No support for versioning
It is possible to version visual programming tools if they store the information in a text based file (e.g XML). Trying to diff raw XML isn’t ideal, but some visual based programming tools do have built-in diff and merge tools.
It isn’t searchable
There is no reason why visual programming tools should not be searchable.
Too much mousing
Professional programmers love their keyboard shortcuts. But there is no reason why visual programming tools can’t also make good use of keyboard shortcuts.
Vendor lock-in
Many visual programming tools are proprietary, which means the cost can be high for switching from one to another. So, if you are going to invest time and/or money heavily in a visual programming tool, take time to make a good choice and consider how you could move away from it if you need to. If you are doing quick and dirty one-offs to solve a particular problem that you don’t need to solve again, then this doesn’t really matter.
‘No code’ just means ‘someone else’s code’
If you are using Python+Pandas or R instead of Easy Data Transform, then you are also balancing on top of an enormous pile of someone else’s code.
We are experts, we don’t need no stinkin drag and drop
If you are an experienced text programmer, then you aren’t really the target market for these tools. Easy Data Transform is aimed at the analyst or business guy trying to wrangle a motley collection of Excel and CSV files, not the professional data scientist who dreams in R or Pandas. However even a professional code jockey might find visual tools faster for some jobs.
Both visual and text programming have their places. Visual programming is excellent for exploratory work and prototyping. Text based programming is almost always a better choice for experts creating production systems where performance is important. When I want to analyse some sales data, I use Easy Data Transform. But when I work on Easy Data Transform itself, I use C++.
Text programming is more mature than visual programming. FORTRAN appeared in the 1950s. Applications with graphical user interfaces only started becoming mainstream in the 1980s. Some of the shortcomings with visual programming reflect it’s relative lack of maturity and I think we can expect to see continued improvements in the tooling associated with visual programming.
Visual programming works best in specific domains, such as:
3d graphics and animations
image processing
audio processing
game design
data wrangling
These domains tend to have:
A single, well defined data type. Such as a table of data (dataframe) for data wrangling.
Well defined abstractions. Such as join, to merge 2 tables of data using a common key column.
A relatively straightforward control flow. Typically a step-by-step pipeline, without loops, recursion or complex control flow.
Visual programming has been much less successful when applied to generic programming, where you need lots of different data types, a wide range of abstractions and potentially complex control flow.
I’ve been a professional software developer since 1987. People (mostly in marketing) have talked about replacing code and programmers with point and click tools for much of that time. That is clearly not going to happen. Text programming is the best approach for some kinds of problems and will remain so for the foreseeable future. But domain-specific visual programming can be very powerful and has a much lower barrier to entry. Visual programming empowers people to do things that might be out of their reach with text programming and might never get done if they have to wait for the IT department to do it.
So, unsurprisingly, the answer to ‘which is better?’ is very much ‘it depends’. Both have their place and neither is going away.
Winterfest 2023 is on. Loads of quality software for Mac and Windows from independent vendors, at a discount. This includes my own Easy Data Transform and Hyper Plan, which are on sale with a 25% discount.
This sounds like a question a programmer might ask after one medicinal cigarette too many. The computer science equivalent of “what is the sounds of one hand clapping?”. But it is a question I have to decide the answer to.
I am adding indexOf() and lastIndexOf() operations to the Calculate transform of my data wrangling (ETL) software (Easy Data Transform). This will allow users to find the offset of one string inside another, counting from the start or the end of the string. Easy Data Transform is written in C++ and uses the Qt QString class for strings. There are indexOf() and lastIndexOf() methods for QString, so I thought this would be an easy job to wrap that functionality. Maybe 15 minutes to program it, write a test case and document it.
Obviously it wasn’t that easy, otherwise I couldn’t be writing this blog post.
First of all, what is the index of “a” in “abc”? 0, obviously. QString( “abc” ).indexOf( “a” ) returns 0. Duh. Well only if you are a (non-Fortran) programmer. Ask a non-programmer (such as my wife) and they will say: 1, obviously. It is the first character. Duh. Excel FIND( “a”, “abc” ) returns 1.
Ok, most of my customers, aren’t programmers. I can use 1 based indexing.
But then things get more tricky.
What is the index of an empty string in “abc”? 1 maybe, using 1-based indexing or maybe empty is not a valid value to pass.
What is the index of an empty string in an empty string? Hmm. I guess the empty string does contain an empty string, but at what index? 1 maybe, using 1-based indexing, except there isn’t a first position in the string. Again, maybe empty is not a valid value to pass.
I looked at the Qt C++ QString, Javascript string and Excel FIND() function for answers. But they each give different answers and some of them aren’t even internally consistent. This is a simple comparison of the first index or last index of text v1 in text v2 in each (Excel doesn’t have an equivalent of lastIndexOf() that I am aware of):
Changing these to make the all the valid results 1-based and setting invalid results to -1, for easy comparison:
So:
Javascript disagrees with C++ QString and Excel on whether the first index of an empty string in an empty string is valid.
Javascript disagrees with C++ QString on whether the last index of an empty string in a non-empty string is the index of the last character or 1 after the last character.
C++ QString thinks the first index of an empty string in an empty string is the first character, but the last index of an empty string in an empty string is invalid.
It seems surprisingly difficult to come up with something intuitive and consistent! I think I am probably going to return an error message if either or both values are empty. This seems to me to be the only unambiguous and consistent approach.
I could return a 0 for a non-match or when one or both values are empty, but I think it is important to return different results in these 2 different cases. Also, not found and invalid feel qualitatively different to a calculated index to me, so shouldn’t be just another number. What do you think?
*** Update 14-Dec-2023 ***
I’ve been around the houses a bit more following feedback on this blog, the Easy Data Transform forum and hacker news and this what I have decided:
IndexOf() v1 in v2:
v1
v2
IndexOf(v1,v2)
1
aba
aba
1
a
a
1
a
aba
1
x
y
world
hello world
7
This is the same as Excel FIND() and differs from Javascript indexOf() (ignoring the difference in 0 or 1 based indexing) only for “”.indexOf(“”) which returns -1 in Javascript.
LastIndexOf() v1 in v2:
v1
v2
LastIndexOf(v1,v2)
1
aba
aba
4
a
a
1
a
aba
3
x
y
world
hello world
7
This differs from Javascript lastIndexOf() (ignoring difference in 0 or 1 based indexing) only for “”.indexOf(“”) which returns -1 in Javascript.
Conceptually the index is the 1-based index of the first (IndexOf) or last (LastIndexOf) position where, if the V1 is removed from the found position, it would have to be re-inserted in order to revert to V2. Thanks to layer8 on Hacker News for clarifying this.
Javascript and C++ QString return an integer and both use -1 as a placeholder value. But Easy Data Transform is returning a string (that can be interpreted as a number, depending on the transform) so we aren’t bound to using a numeric value. So I have left it blank where there is no valid result.
Now I’ve spent enough time down this rabbit hole and need to get on with something else! If you don’t like it you can always add an If with Calculate or use a Javascript transform to get the result you prefer.
*** Update 15-Dec-2023 ***
Quite a bit of debate on this topic on Hacker News.
Summerfest 2023 is on. Loads of quality software for Mac and Windows from independent vendors, at a discount. This includes my own Easy Data Transform and Hyper Plan, which are on sale with a 25% discount.
Easy Data Transform and Hyper Plan Professional edition are both on sale for 25% off at Winterfest 2022. So now might be a good time to give them a try (both have free trials). There is also some other great products from other small vendors on sale, including Tinderbox, Scrivener and Devonthink. Some of the software is Mac only, but Easy Data Transform and Hyper Plan are available for both Mac and Windows (one license covers both OSs).